Topics covered:
Learning machine learning fundamentals including:
- linear algebra review
- automatic regression and classifcation fitting models
- building complex neural networks (deep models)
Learn the fundamentals of PyTorch for basic deep learning models
- efficient computation/storage
- computational graphs/back-propagation
- formatting data and training NN models
Advanced machien learning topics
- advanced deep network concepts like attention (transformer models)
- large language models basics and usage
Big goal: learn machine learning basics through applications. (Theory is awesome, but most of us just want to passs a interview)
View course website and show the following:
- Course staff
- Course structure
- Homeworks
- Exams
- Project
Lecture plan:¶
- Introduction to PyTorch
- Sample PyTorch Code
- Tensor Basics
- Tensor Operations
Part 1: Introduction to PyTorch¶
What is PyTorch?¶
PyTorch is a open-source machine learning library used for various tasks that require some level of model optimization like natural language processing, computer vision.
- Originally developed by Meta AI and now a part of the Linux Foundation
- Developed in conjunction with with Convolutional Architecture for Fast Feature Encoding (Caffe2) (C++ machine learning framework)
- But models between frameworks were incompatible ...
- So Meta and Microsoft created the Open Neural Network Exchange (ONNX) for converting ML models between frameworks
- Caffe2 was merged into PyTorch 2 years later
- PyTorch 2 was released in 2023 and introduced TorchDynamo, a Python level compiler that offered a lot of ML specific optimizations and significant speed-ups
Why use PyTorch¶
When PyTorch was introduced in 2017, Tensorflow and Keras (Tersorflow wrapper) were already mature machine learning libraries. But now 85% of academic papers use PyTorch: why?
- Simplicity - easy to use, extend and debug
- Python integration - Python is now the most popular language in the world
- The tensor data type, perfect abstraction of NumPy data
- Accelerated computation using GPUs
- Early Caffe2 integration gave it a high performing C++ compiler
Part 2: Feeling out PyTorch¶
Software installation and initialization¶
Install PyTorch using anaconda or pip
Check your successful installation using the following code
import numpy as np
print(np.__version__)
1.26.4
import torch
print(torch.__version__)
2.2.2
Datasets¶
Many classic datasets come preprogrammed into PyTorch
Let's look at one of these datasets: CIFAR-10
*Due to licensing issues CIFAR is no longer a default in the PyTorch library but it is still easily accessible
import numpy as np
import torch
import torch.nn as nn
from torchvision import datasets
from torchvision import transforms
from torch.utils.data.sampler import SubsetRandomSampler
#credit to https://jamesmccaffrey.wordpress.com/2020/08/07/displaying-cifar-10-images-using-pytorch/
import torch as T
import torchvision as tv
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy() # convert from tensor
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
transform = transforms.Compose( [transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))])
trainset = tv.datasets.CIFAR10(root='.\\data', train=True, download=True, transform=transform)
trainloader = T.utils.data.DataLoader(trainset,
batch_size=100, shuffle=False, num_workers=1)
# classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog',
# 'frog', 'horse', 'ship', 'truck')
# get first 100 training images
dataiter = iter(trainloader)
imgs, lbls = next(dataiter)
for i in range(100): # show just the frogs
if lbls[i] == 1: # 1 = car
imshow(tv.utils.make_grid(imgs[i]))
Jupyter notebook demonstration (on Google colab)¶
- http://colab.research.google.com (provides access to GPUs and TPUs)
Part 3: Introduction to Tensors¶
Let's think about vectors and how we would initialize/use them:
vec1 = [1,2,3]
print(vec1)
[1, 2, 3]
import numpy as np
vec2 = np.array(vec1)
print(vec2)
[1 2 3]
Why do we use numpy if vanilla python has arrays/matrices anyway?
import time
import numpy as np
size_of_vec = int(1e6)
def pure_python_version():
t1 = time.time()
X = range(size_of_vec)
Y = range(size_of_vec)
Z = [X[i] + Y[i] for i in range(len(X)) ]
return time.time() - t1
t1 = pure_python_version()
print('Pure Python time: {:.6f}'.format(t1))
Pure Python time: 0.228560
def numpy_version():
t1 = time.time()
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
Z = X + Y
return time.time() - t1
t2 = numpy_version()
print('Numpy time: {:.6f}'.format(t2))
Numpy time: 0.015880
Why does NumPy perform so much faster than normal Python arrays (Hint, isn't the lack of commas weird)?
What about tensors?¶
- Vectors are 1-D arrays
- Matrices are 2-D arrays
- Tensors are n-dimensional arrays of various sizes
How to create a Torch tensor¶
a = [[j+3*i for j in range(3)] for i in range(2)]
print(a)
np_array = np.array(a)
print(np_array)
#Initialize from normal python array
import torch
a_data = torch.tensor(a)
print(a_data)
#Initialize from NumPy array
a_np = torch.from_numpy(np_array)
print(a_np)
Useful tensor initializations:¶
shape = (2,3,4)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print("Random Tensor: \n {} \n".format(rand_tensor))
print("Ones Tensor: \n {} \n".format(ones_tensor))
print("Zeros Tensor: \n {}".format(zeros_tensor))
Some simple Tensor Attributes¶
tensor = torch.rand(3,4)
print("Shape of tensor: {}".format(tensor.shape))
print("Datatype of tensor: {}".format(tensor.dtype))
print("Device tensor is stored on: {}".format(tensor.device))
Tensor indexing¶
Tensors can be indexed just like NumPy arrays
a = [[j+3*i for j in range(3)] for i in range(2)]
a_tensor = torch.tensor(a)
print(a_tensor)
# example of slicing
print(a_tensor[:,1])
print(a_tensor[1,0].item())
torch.manual_seed(42)
# Generate random integers
aa = torch.randint(0, 100, (2, 3, 4))
print(aa)
print(aa)
Alertness Check - What is the index of the value "78" ?
print(aa[0][0][0])
print(aa.shape)
Basic Tensor Operations¶
Same idea as with NumPy arrays/matrices
a = [[i+3*j for i in range(3)] for j in range(2)]
b = [[j+2*i for i in range(3)] for j in range(2)]
c = [[int(i+3*j%2==1) for i in range(2)] for j in range(3)]
a_tensor = torch.tensor(a)
b_tensor = torch.tensor(b)
c_tensor = torch.tensor(c)
print(a_tensor)
print(b_tensor)
print(c_tensor)
# This computes the ****** product
print(f"a_tensor.mul(b_tensor) \n {a_tensor.mul(b_tensor)} \n")
# Alternative syntax:
print(f"a_tensor * b_tensor \n {a_tensor * b_tensor}")
print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n")
# Alternative syntax:
print(f"tensor @ tensor.T \n {tensor @ tensor.T}")
# This transposes a tensor
print('Original tensor \n {} \n'.format(a_tensor))
print('Transposed tensor \n {} \n'.format(a_tensor.T))
print('Another way to transpose the tensor \n {} \n'.format(torch.transpose(a_tensor, dim0=0, dim1=1)))
Alertness check: Why is there a a dim0/dim1 option in tensor.transpose?
x = torch.tensor([[[i for k in range(4)] for j in range(3)] for i in range(2)])
print(x.shape)
print("Original Vector:")
print(x)
Let's say we want to change x to be a $4\times 3 \times 2$ tensor? How to we transpose it?
print("Original Vector:")
print(x)
print("Transposed Vector (Dim = ?):")
xt=torch.transpose(x, dim0=0, dim1=1)
print(xt)
print(print(xt.shape))
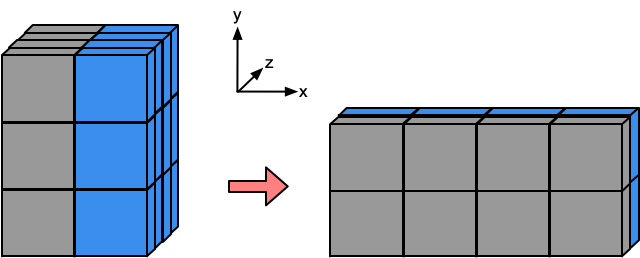
What if we do x.T?
print(x.T)
Elementwise operations¶
Many functions can be applied on a tensor element by element
- torch.cos
- torch.sin
- torch.exp
- torch.log
These functions return a new tensor with the function being applied to each element in the tensor
a = torch.ones([4,4])
b = torch.log(a)
print(a)
print(b)
In-place operations¶
Operations that have a _ suffix are in-place. For example: x.copy_(y), x.t_(), x.exp_(), will change x.
print(tensor, "\n")
tensor.add_(5)
print(tensor)
Interaction with NumPy¶
You'll likely need to convert between a NumPy array (usually when plotting data/results).
# Convert from tensor to NumPy array
tensor = torch.ones(4, 4)
print(tensor)
print(tensor.numpy())
# Covert from NumPy array to torch:
n = np.ones(5)
t = torch.from_numpy(n)
print(t)
Cool thing is that changes in NumPy array are reflected in the tensor!
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")
Both numpy array and tensor data point to the same contiguous block in memory. Very different than view, speaking of which:
Tensor Views¶
Imagine we want to access part of a tensor (e.g., first row) or we want to permute rows and columns. Do we really need to allocate new memory to store this part of the tensor?
No:
- a tensor can be a "view" of an existing tensor
- a "view" of a tensor shares the data with the original tensor
a = torch.tensor([[4*i+j for j in range(4)] for i in range(4)])
b = a.view(2, 8)
print(a)
print(b)
How much memory does a and b consume?
import sys
print("a is sized: " + str(sys.getsizeof(a)))
print("b is sized: " + str(sys.getsizeof(b)))
Makes sense right?
c = torch.tensor([[4*i+j for j in range(100)] for i in range(100)])
print("c is sized: " + str(sys.getsizeof(c)))
print("The data in 'a' is sized: " + str(a.element_size() * a.nelement()))
print("The data in 'b' is sized: " + str(b.element_size() * b.nelement()))
print("The data in 'c' is sized: " + str(c.element_size() * c.nelement()))
a = torch.tensor([[4*i+j for j in range(4)] for i in range(4)])
b = a.view(-1, 16)
c = torch.tensor([[5*i+j for j in range(5)] for i in range(5)])
def same_storage(x, y):
return x.storage().data_ptr() == y.storage().data_ptr()
print("Do 'a' and 'b' share a view? " + str(same_storage(a, b)))
print("Do 'a' and 'c' share a view? " + str(same_storage(a, c)))
Hard to know what creates a view and what creates a copy, but general rule of thumb is that a view is created unless there are no other options:
| Creates tensor views | Creates tensor copies |
|---|---|
view() - reshapes tensor |
clone() - explicity creates a copy |
narrow() - extracts contiguous subset of tensor |
detach() - creates a new tesnor detached from computational graph |
transpose() - swaps two dimensions of a tensor |
copy() - copies data from one tensor to another |
permute() - generalizes transpose to many dimensions |
to() - copies data to gpu |
squeeze() - removes dimensions of size 1 |
|
unsqueeze() - add dimension of size 1 |
|
as_strided() - creates a view with non-contiguous strides (advanced) |
Tensor strides¶
How do we create a new tensor with different dimensions, but with the same data?
strides
Imagine that this is a tensor:
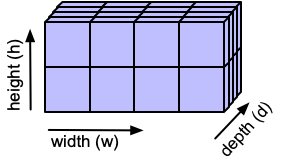
The tensor class hold many properties:
- sizes: (w,h,d)
- dtype: int/float/...
- device: cpu/gpu
- layout: strided
- strides: (w*h, w, 1)
Strided representation:
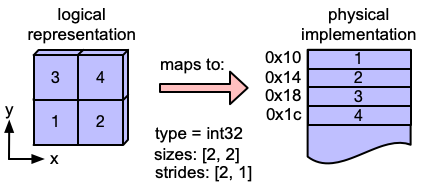
So for instance, the element at index [1,0] corresponds to the memory at: base_ptr + (1stride[0] + 0stride[1])*size(dtype)
For the left example it would be: 0x10+(12+01)*4=0x18
*credit to: http://blog.ezyang.com/2019/05/pytorch-internals/
Combining Tensors¶
We can concatenate tensors along different dimensions that already exist! All other dimensions must match.
a = torch.randn(2,3)
b = torch.cat((a,a,a),dim=0)
c = torch.cat((a,a,a),dim=1)
print('Original tensor')
print(a.shape)
print(a)
print('')
print('Concatenate in dimension 0 (rows)')
print(b.shape)
print(b)
print('')
print('Concatenate in dimension 1 (rows)')
print(c.shape)
print(c)
We can also stack tensors along a new dimension
a = torch.randn(2,3)
b = torch.stack((a,a,a,a),dim=0)
c = torch.stack((a,a,a,a),dim=1)
d = torch.stack((a,a,a,a),dim=2)
print('Original tensor')
print(a.shape)
print(a)
print('')
print('Stack in dimension 0')
print(b.shape)
print(b)
print('')
print('Stack in dimension 1')
print(c.shape)
print(c)
print('Stack in dimension 2')
print(d.shape)
print(d)
Adding dimensions¶
We can also add dimensions if we need them
a = torch.randn(2,3)
b = a.unsqueeze(0)
print(a.shape)
print(b.shape)
c = b.squeeze(0)
print(c.shape)
Datatypes of tensors¶
Recall different datatypes from ECE 220
- 8-bit signed integer (char): torch.int8
- 8-bit unsigned integer (unsigned char): torch.uint8
- 32-bit signed integer (int): torch.int32
- 32-bit floating point (float): torch.float (or torch.float32)
- 64-bit floating point (double): torch.double (or torch.float64)
a = torch.zeros([2, 5], dtype=torch.int32)
print(a)
# a.element_size() gives memory (in bytes) per element in tensor
# a.nelement() gives number of elements in a tensor
print(a.element_size() * a.nelement())
b = torch.ones([3, 5], dtype=torch.float64)
print(b)
print(b.element_size() * b.nelement())
# think of this tensor as (# images, # channels, height, width)
c = torch.rand([8, 128, 224, 224], dtype=torch.float64)
print('c takes {} MB'.format(c.element_size() * c.nelement()/(2**20)))
How much memory do those tensors consume (roughly)?
It is important to roughly keep track of how much memory your machine learning/artificial intelligence application uses because GPU memory is often a main limitation
Converting from one datatype to another¶
Use the Tensor.to(...) function but keep in mind possible loss of bits
x = torch.ones((2,4), dtype=torch.int32)
print(x)
y = x.to(torch.float64)
print(y)