Things we will cover:
Last lecture we discussed linear regression and specifically we focused on one-dimensional linear fits:
$$ y = mx + b $$This is called simple linear regression.
When we have multiple input parameters that we wish to regress on:
$$ y = m_nx_n \ldots + m_3x_3 + m_2x_2 + m_1x_1 + b $$This is called multiple linear regression.
import numpy as np
import torch
import matplotlib.pyplot as plt
# dataset we are artificially creating:
# Set seed for reproducibility
np.random.seed(42)
# Generate 10 x values between 0 and 10
DN=11
x = torch.linspace(0, 10, DN)
y = torch.linspace(0, 10, DN)
points = torch.stack(torch.meshgrid(x, y)).T.reshape(-1,2)
X = torch.column_stack((torch.ones(points.shape[0]), points))
N = X.shape[0]
#print(X)
# Generate true target values with some noise
true_b = 3
true_m1 = 3
true_m2 = 1
t = true_b + true_m1*X[:,1] + true_m2*X[:,2] + 2.0*torch.randn(X.shape[0], dtype=X.dtype)
# initialize guesses for w, b
w_gd = torch.randn((3), requires_grad=True) # size (1,)
print('Initial guesses: w0={:.6f}, w1={:.6f}, w2={:.6f}'.format(w_gd[0].data, w_gd[1].data, w_gd[2].data))
# information for tracking
b_vals = [w_gd[0].data.item()]
w1_vals = [w_gd[1].data.item()]
w2_vals = [w_gd[2].data.item()]
# gradient descent loop
n_iter = 10000 # number of iterations
alpha = 10e-3 # step size
for n in range(n_iter):
errors = t-(X@w_gd)
loss = torch.sum((errors)**2)/N
loss.backward()
with torch.no_grad():
w_gd -= alpha*w_gd.grad
w_gd.grad = None
# log information
w2_vals.append(w_gd[2].data.item())
w1_vals.append(w_gd[1].data.item())
b_vals.append(w_gd[0].data.item())
# examine solution
print('Final guesses: w0={:.6f}, w1={:.6f}, w2={:.6f}'.format(w_gd[0].data, w_gd[1].data, w_gd[2].data))
iter_num = np.array([0, 50, 100, 250, 500]).astype(int)
plt.figure(figsize=(20, 5))
for j, i in enumerate(iter_num):
ax = plt.subplot(1, 5, j+1, projection='3d')
ax.scatter(X[:,1].detach().numpy(), X[:,2].detach().numpy(), t, color='green')
xx, yy = torch.meshgrid(x, y)
curr_fn = w2_vals[i]*yy + w1_vals[i]*xx + b_vals[i]
ax.plot_surface(xx, yy, curr_fn.detach().numpy(), color='blue', alpha=0.5)
plt.grid(True)
plt.title('Regressed function: Iteration {}'.format(i))
Initial guesses: w0=0.016773, w1=0.372039, w2=-0.729737 Final guesses: w0=2.803721, w1=3.030293, w2=1.030664

W = torch.linalg.inv(X.t()@X)@X.t()@t
print(W)
tensor([2.8038, 3.0303, 1.0307])

from sklearn.datasets import fetch_california_housing
import torch
# Load the dataset
california_housing = fetch_california_housing()
# Extract features and target
X = california_housing.data
t = california_housing.target
# Convert to PyTorch tensors
X_tensor = torch.tensor(X, dtype=torch.float32)
t_tensor = torch.tensor(t, dtype=torch.float32).view(-1)
import matplotlib.pyplot as plt
# Feature names
feature_names = california_housing.feature_names
# Create a figure with subplots
fig, axes = plt.subplots(nrows=2, ncols=4, figsize=(20, 10))
axes = axes.flatten()
# Plot each feature against the target
for i, feature in enumerate(feature_names):
axes[i].scatter(X[:, i], t, alpha=0.5)
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Median House Value')
axes[i].set_title(f'{feature} vs. Median House Value')
# Adjust layout
plt.tight_layout()
plt.show()

N = X_tensor.shape[0]
X = torch.column_stack((torch.ones(N), X_tensor))
w_gd = torch.randn((X_tensor.shape[1]+1), requires_grad=True) # size (1,)
print('Initial guesses: ' + str(w_gd))
# information for tracking
w_vals = []
w_vals.append(w_gd.detach().numpy())
loss_vals = []
# gradient descent loop
n_iter = 2 # number of iterations
alpha = 0.01e-3 # step size
for n in range(n_iter):
# compute loss function (objective function)
errors = t_tensor-(X@w_gd)
loss = torch.sum((errors)**2)/N
# backpropagate gradients
loss.backward()
# perform gradient descent update step
with torch.no_grad():
# don't want the gradient update step to accumulate further gradients at a, b, and c
w_gd -= alpha*w_gd.grad
# manually zero out the gradients before next backward pass
w_gd.grad = None
# log information
loss_vals.append(loss.item()) # log MSE
w_vals.append(w_gd.detach().numpy())
# examine solution
print('Final guesses: ' + str(w_gd))
Initial guesses: tensor([ 0.6398, 0.4604, 0.8651, 0.7756, -0.5902, -0.4344, 2.0569, -2.7836,
-0.0030], requires_grad=True)
Final guesses: tensor([-2.1091e-01, -2.8386e+00, -2.0991e+01, -3.7224e+00, -1.5020e+00,
-1.9766e+03, -1.0536e+00, -3.2939e+01, 1.0158e+02],
requires_grad=True)
print(feature_names)
W = torch.linalg.inv(X.t()@X)@X.t()@t_tensor
print(W)
['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
tensor([-3.6760e+01, 4.3717e-01, 9.4781e-03, -1.0779e-01, 6.4664e-01,
-5.6005e-06, -3.7917e-03, -4.1936e-01, -4.3244e-01])

Suppose we had the following plot:
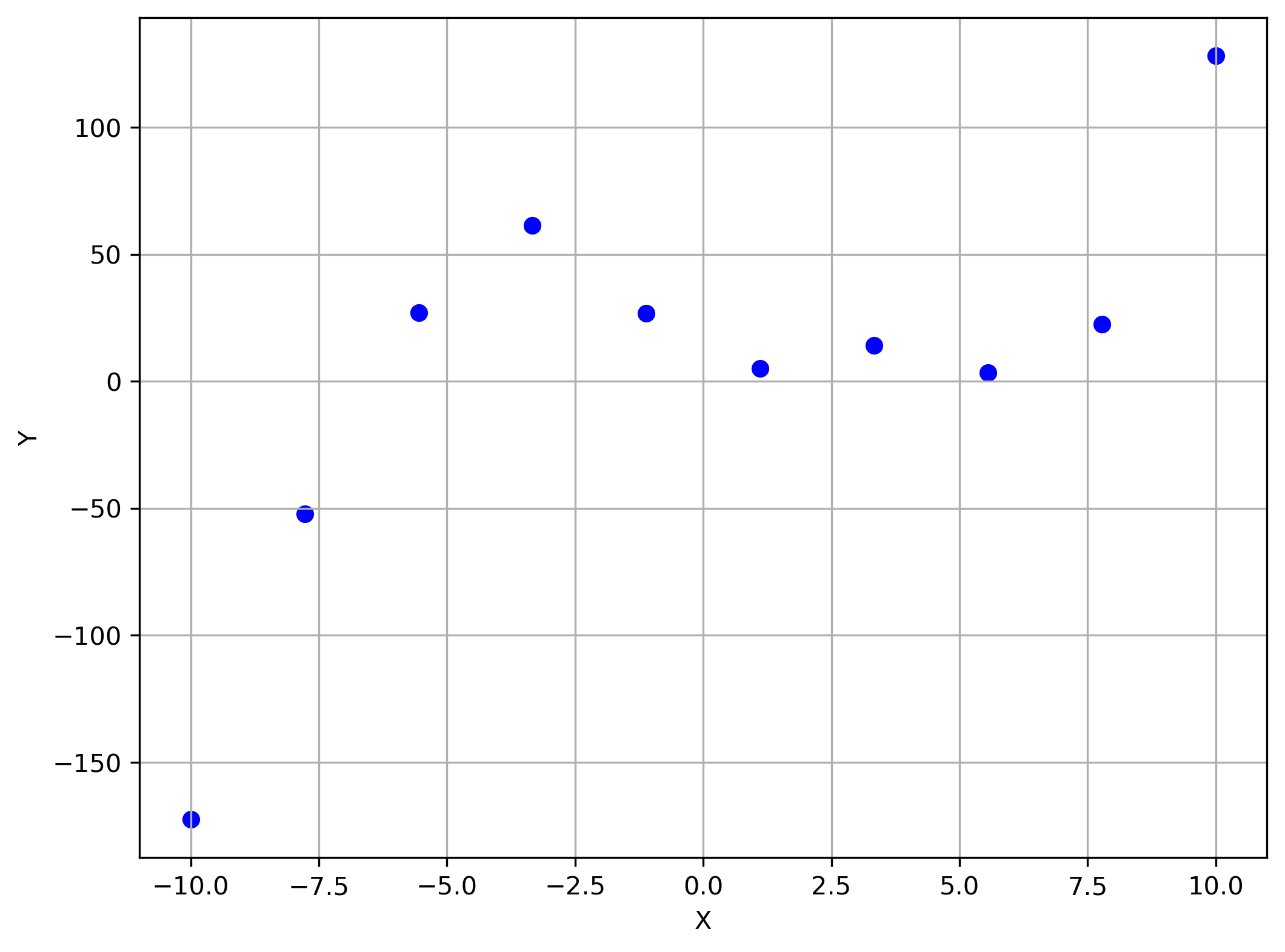
Linear model here would probably be less than ideal...... what do we do?
Linear model here is less than ideal...... what do we do?
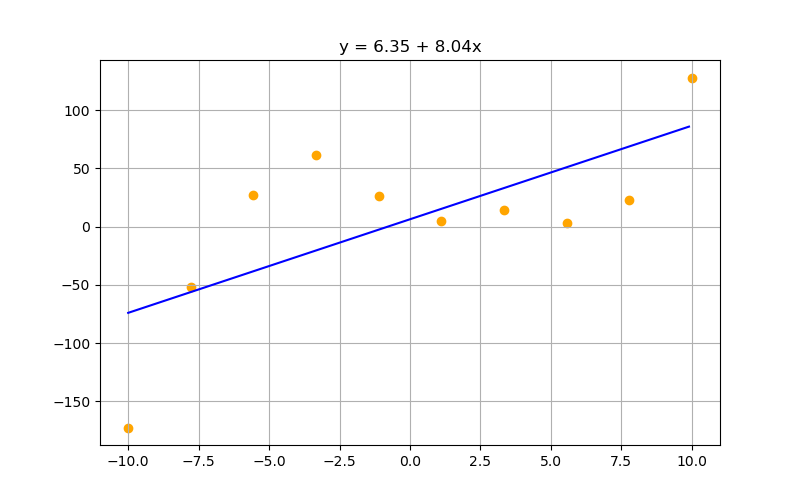
Well think of the last few lectures. We had plenty of complex functions we fitted our data to .... What were we doing then?
A complex polynomial is simply the combination of a bunch of powers of $x$. So if we can combine linear functions together, why not combine polynomial function together also?
We do this by augmenting our prior work using a feature map:
$$\phi(x) = \begin{pmatrix} 1 \\ x \\ x^2 \\ x^3 \end{pmatrix}$$making the regression model:
$$ y = w^T \phi(x) $$All of the derivations in the lecture so far are going to remain the same!
import numpy as np
import torch
import matplotlib.pyplot as plt
# dataset we are artificially creating:
# Set seed for reproducibility
np.random.seed(42)
N=10
# Generate 10 x values between 0 and 10
x = torch.linspace(-10, 10, N)
# Generate y values with some variability
def f(x):
return 0.25 * x **3 + -0.5 * x**2 + -10 * x + 20
t = torch.clone(f(x) + np.random.normal(0, 15, size=len(x)))
#Set polynomial order (2 means we want a fitting function w3 x^3 + w2 x^2 + w1 x + w0)
order = 3
def f_fit(w, x):
out = w[0]
for i in (1+np.arange(order)):
a = w[i] * x**i
b = out
out = a + b
return out
# initialize guesses for w, b
w_gd = torch.randn((order+1), requires_grad=True) # size (1,)
print('Initial guesses: ' + str(w_gd))
n_iter = 200000 # number of iterations
alpha = 1e-6 # step size
momentum = 0.9
velocity = torch.zeros(order+1)
w_vals = []
w_vals.append(w_gd.detach().numpy().copy())
for n in range(n_iter):
y = sum(w_gd[i] * x**i for i in torch.arange(order+1))
errors = t-y
loss = torch.sum((errors)**2)/N
loss.backward()
with torch.no_grad():
velocity.mul_(momentum).add_(w_gd.grad, alpha=-alpha)
w_gd.add_(velocity)
w_gd.grad.zero_()
# velocity = velocity*momentum - alpha*w_gd
# w_gd = torch.tensor(w_gd + velocity, requires_grad=True)
w_vals.append(w_gd.detach().numpy().copy())
# examine solution
print('Final guesses: ' + str(w_gd))
plt.figure(figsize=(8, 5))
plt.subplot(1, 1,1)
xx = np.arange(-10,10,0.1)
curr_fn = np.zeros_like(xx)
for k in range(xx.shape[0]):
curr_fn[k] = sum(w_gd[a] * xx[k]**a for a in np.arange(order+1))
plt.plot(xx, curr_fn, color='blue')
plt.scatter(x.detach().numpy(), t, color='orange')
plt.grid(True)
plt.title('Regressed function: w_0'.format(i))
# iter_num = np.array([0, 20000, 40000, 100000, 200000]).astype(int)
# plt.figure(figsize=(20, 5))
# for j, i in enumerate(iter_num):
# plt.subplot(1, 5, j+1)
# curr_fn = w_vals[i]*x + b_vals[i]
# plt.plot(x.detach().numpy(), curr_fn.detach().numpy(), color='blue')
# plt.scatter(x.detach().numpy(), t, color='orange')
# plt.grid(True)
# plt.title('Regressed function: Iteration {}'.format(i))
Initial guesses: tensor([ 1.3396, -0.1014, -0.8522, -0.8095], requires_grad=True) Final guesses: tensor([ 23.7810, -10.0547, -0.4786, 0.2501], requires_grad=True)
Text(0.5, 1.0, 'Regressed function: w_0')

iter_num = np.array([0, 5000, 20000, 50000, 200000]).astype(int)
plt.figure(figsize=(20, 5))
for j, i in enumerate(iter_num):
plt.subplot(1, 5, j+1)
xx = np.arange(-10,10,0.1)
curr_fn = np.zeros_like(xx)
print(w_vals[i])
for k in range(xx.shape[0]):
curr_fn[k] = sum(w_vals[i][a] * xx[k]**a for a in np.arange(order+1))
plt.plot(xx, curr_fn, color='blue')
plt.scatter(x.detach().numpy(), t, color='orange')
plt.grid(True)
plt.title('Regressed function: Iteration {}'.format(i))
[ 0.6529619 -1.364675 -0.62764525 0.14843452] [ 1.8479408 -5.309503 -0.17538156 0.19427092] [ 5.123281 -9.287068 -0.2206618 0.24108562] [ 10.516496 -10.038336 -0.29522064 0.2499278 ] [ 23.66065 -10.054739 -0.4769331 0.25012088]

What's interesting is that the exact same logic we used to get the matrix solution for linear regression last lecture also works here! We just got to define a few things:
$$ y = w_0 + w_1 x + w_2 x^2 + \cdots + w_n x^m $$In this equation:
Now we can redefine the system:
$$ \begin{bmatrix} y_1 \\ y_2 \\ y_3 \\ \vdots \\ y_n \end{bmatrix} = \begin{bmatrix} 1 & x_1 & x_1^2 & \cdots & x_1^m \\ 1 & x_2 & x_2^2 & \cdots & x_2^m \\ 1 & x_3 & x_3^2 & \cdots & x_3^m \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_n & x_n^2 & \cdots & x_n^m \end{bmatrix} \begin{bmatrix} w_0 \\ w_1 \\ w_2 \\ \vdots \\ w_m \end{bmatrix} $$which can then be written as
$$ Y = XW $$So how does this help us? Remember what we did last lecture. We had the loss:
$$ \begin{align} \mathcal{L} &= \arg\min_{W} \frac{1}{2} \sum_{i=1}^{N} \left( t^{(i)} - y^{(i)} \right)^2\\ \mathcal{L} &= \arg\min_{W} \frac{1}{2} \sum_{i=1}^{N} \left( t^{(i)} - X^{(i)} W \right)^2 \\ \mathcal{L} &= \arg\min_{W} \frac{1}{2} \left( T - X^T W \right)^2 \\ \mathcal{L} &= \arg\min_{W} \frac{1}{2} \left( T - X^T W \right)^T \left( T - X^T W \right) \\ \mathcal{L} &= \arg\min_{W} \frac{1}{2} \left( T^T T - T^T X^T W - W^T X T + W^T X X^T W \right) \\ \end{align} $$to find the minimum we take the derivative of the loss and set it equal to zero:
$$ \begin{align} \frac{\partial \mathcal{L}}{\partial W} = 0 &= 0 - T^T X^T - X T + 2 X X^T W \\ &= - X T - X T + 2 X X^T W \\ 2XT &= 2 X X^T W \\ X X^T W &= XT \\ W &= \left(X X^T\right)^{-1} X T \end{align} $$this means that using the exact same logic as last lecture, we get:
$$ W = \left(X^TX\right)^{-1}X^T T $$(Both formulations are correct, just depends on how you define the initial loss function. Thought I'd show an alternate formulation)
def polynomial_to_string(coefficients):
"""
Converts a list of coefficients into a polynomial equation string with coefficients
formatted to two decimal places.
Parameters:
coefficients (list or array): Coefficients of the polynomial, where the index represents the power of x.
Returns:
str: A string representation of the polynomial equation.
"""
terms = []
degree = len(coefficients) - 1
for power, coeff in enumerate(coefficients):
if coeff == 0:
continue # Skip zero coefficients
# Determine the sign
sign = '+' if coeff > 0 else '-'
# Format the coefficient to two decimal places
abs_coeff = abs(coeff)
if abs_coeff == 1 and power != 0:
coeff_str = ''
else:
coeff_str = f'{abs_coeff:.2f}'
# Format the variable part
if power == 0:
variable_str = ''
elif power == 1:
variable_str = 'x'
else:
variable_str = f'x^{power}'
# Combine parts
if terms:
term = f' {sign} {coeff_str}{variable_str}'
else:
term = f'{coeff_str}{variable_str}' if sign == '+' else f'-{coeff_str}{variable_str}'
terms.append(term)
# Join all terms and handle the case where all coefficients are zero
polynomial = ''.join(terms) if terms else '0'
return f'y = {polynomial}'
# Example usage:
coefficients = [2, -4.5678, 0, 3.14159] # Represents 2 - 4.57x + 3.14x^3
equation = polynomial_to_string(coefficients)
print(equation) # Output: y = 2.00 - 4.57x + 3.14x^3
y = 2.00 - 4.57x + 3.14x^3
import numpy as np
import torch
import matplotlib.pyplot as plt
# dataset we are artificially creating:
# Set seed for reproducibility
np.random.seed(42)
N=10
# Generate 10 x values between 0 and 10
x = torch.linspace(-10, 10, N)
# Generate y values with some variability
def f(x):
return 0.25 * x **3 + -0.5 * x**2 + -10 * x + 20
t = torch.clone(f(x) + np.random.normal(0, 15, size=len(x)))
#Set polynomial order (2 means we want a fitting function w3 x^3 + w2 x^2 + w1 x + w0)
order = 3
X = np.ones(N)
for i in range(order):
XC = x**(i+1)
X = np.column_stack((X, XC))
w = np.matmul(np.matmul(np.linalg.inv(np.matmul(X.transpose(),X)), X.transpose()), t)
print(w)
plt.figure(figsize=(8, 5))
plt.subplot(1, 1,1)
xx = np.arange(-10,10,0.1)
curr_fn = np.zeros_like(xx)
for k in range(xx.shape[0]):
curr_fn[k] = sum(w[a] * xx[k]**a for a in np.arange(order+1))
plt.plot(xx, curr_fn, color='blue')
plt.scatter(x.detach().numpy(), t, color='orange')
plt.grid(True)
plt.title(polynomial_to_string(w))
tensor([ 28.5155, -10.0587, -0.5440, 0.2502], dtype=torch.float64)
Text(0.5, 1.0, 'y = 28.52 - 10.06x - 0.54x^2 + 0.25x^3')

With this new ability, it is tempting to just go to the highest degree polynomial that looks good, but ask yourself, is the model representative of the underlying model?
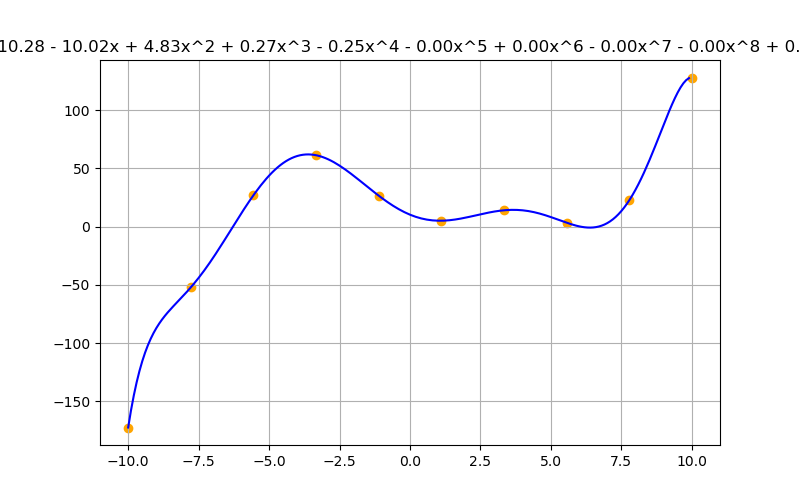
import numpy as np
import matplotlib.pyplot as plt
# Set seed for reproducibility
np.random.seed(42)
# Generate 10 x values between 0 and 10
x = np.linspace(-10, 10, 10)
# Generate y values with some variability
def f(x):
return 0.25 * x **3 + -0.5 * x**2 + -10 * x + 20
y = f(x) + np.random.normal(0, 15, size=len(x))
# Create the figure and axis
plt.figure(figsize=(8, 6))
# Scatter plot of generated points
plt.scatter(x, y, label='Generated Data', color='blue')
# Plot the line
px = np.linspace(-10, 10, 100)
# plt.plot(px,f(px), label='y = 2x + 5', color='blue', linewidth=2)
# Labels and title
plt.xlabel('X')
plt.ylabel('Y')
#plt.ylim(0, 30)
#plt.title('Scatter Plot with Best Fit Line (Seed = 42)')
#plt.legend()
plt.grid(True)
#plt.show()
# Save the plot to a file
plt.savefig("./img/scatter_plot_with_sample_polynomial_no_lines.png", dpi=300, bbox_inches='tight')

Let's assume we know all the parameters are roughly the same order of magnitude. Maybe we can encourage the model to normalize the parameters to minimize one parameter getting pulled a particular way?
We can what's called a L2 penalty term to the loss function, and this is called L2 regularization.:
$$ \mathcal{L}(w) = \sum_{i=1}^{n} \left( y^i - wx^i \right)^2 + \lambda \sum_{j=0}^{d} w_j^2 $$where $\lambda$ is a fitting term. This is called L2 penalty just because it’s a L2-norm of ( w ).
In fancy terms, this whole loss function is also known as Ridge regression.
Interestingly, the same matrix solution we've developed for the matrix solution can be modified to include L2 regularization:
"First write the loss function in matrix notation:
$$ L(w) = \|y - Xw\|^2 + \lambda \|w\|^2_2 $$Then the gradient is:
$$ \nabla L_w = -2X^T(y - Xw) + 2\lambda w $$Setting to zero and solving:
$$ 0 = -2X^T(y - Xw) + 2\lambda w $$$$ = X^T(y - Xw) - \lambda w $$$$ = X^T y - X^T X w - \lambda w $$$$ = X^T y - (X^T X + \lambda I_d) w $$Move that to the other side and we get a closed-form solution:
$$ (X^T X + \lambda I_d) w = X^T y $$$$ W = (X^T X + \lambda I_d)^{-1} X^T y $$which is almost the same as linear regression without regularization." [2]
import numpy as np
import torch
import matplotlib.pyplot as plt
# dataset we are artificially creating:
# Set seed for reproducibility
np.random.seed(42)
N=10
# Generate 10 x values between 0 and 10
xlims = [-10, 10]
x = torch.linspace(xlims[0], xlims[1], N)
# Generate y values with some variability
def f(x):
return -1 * x + 1
random_spikes = np.zeros(N)
random_spikes[1] = 35
random_spikes[7] = 55
t = f(x) + np.random.normal(0, 0.5, size=len(x)) + random_spikes
#Set polynomial order (2 means we want a fitting function w3 x^3 + w2 x^2 + w1 x + w0)
order = 1
X = np.ones(N)
for i in range(order):
XC = x**(i+1)
X = np.column_stack((X, XC))
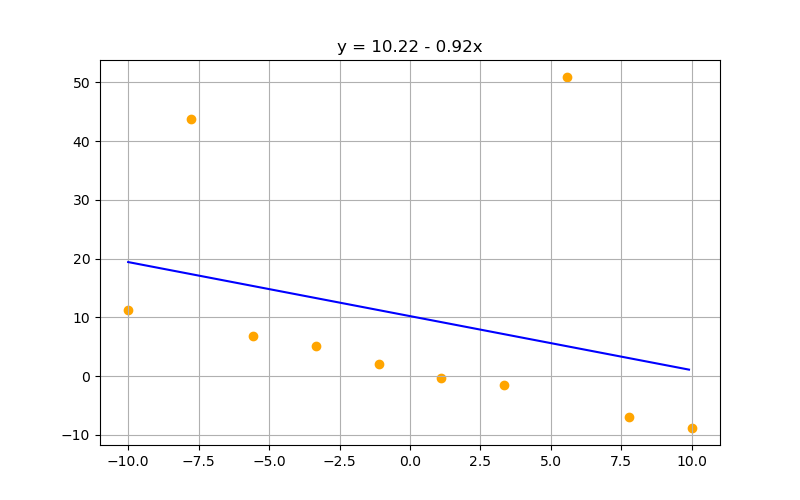
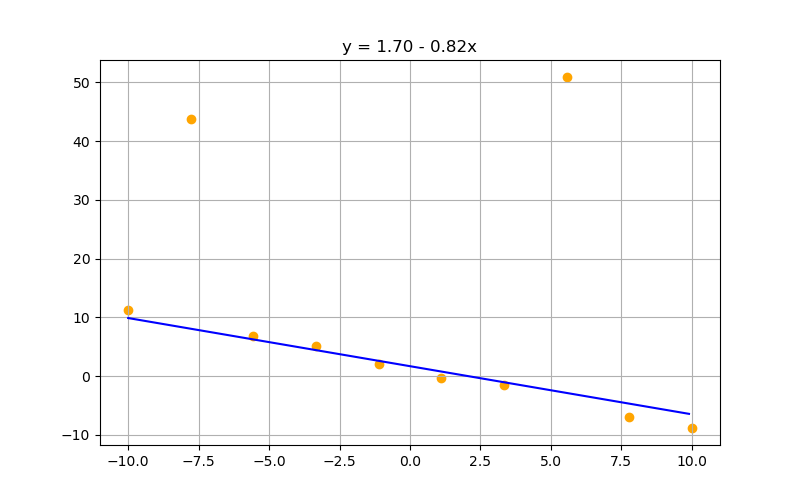
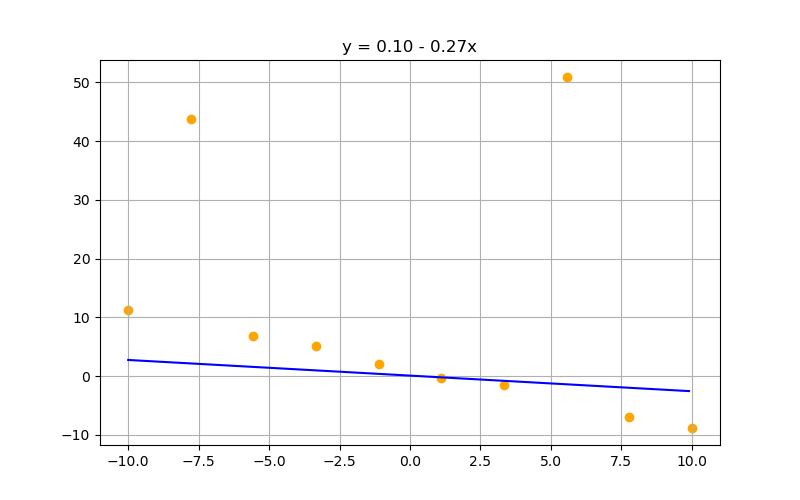
lambdaa = 50
w = np.matmul(np.matmul(np.linalg.inv(np.matmul(X.transpose(),X) + lambdaa*np.identity(order+1)), X.transpose()), t)
print(w)
plt.figure(figsize=(8, 5))
plt.subplot(1, 1,1)
xx = np.arange(min(x), max(x), 0.1)
curr_fn = np.zeros_like(xx)
for k in range(xx.shape[0]):
curr_fn[k] = sum(w[a] * xx[k]**a for a in np.arange(order+1))
plt.plot(xx, curr_fn, color='blue')
plt.scatter(x, t, color='orange')
plt.grid(True)
plt.title(polynomial_to_string(w))
plt.savefig('./img/reg_example_lambda='+str(lambdaa))
tensor([ 1.7040, -0.8192], dtype=torch.float64)

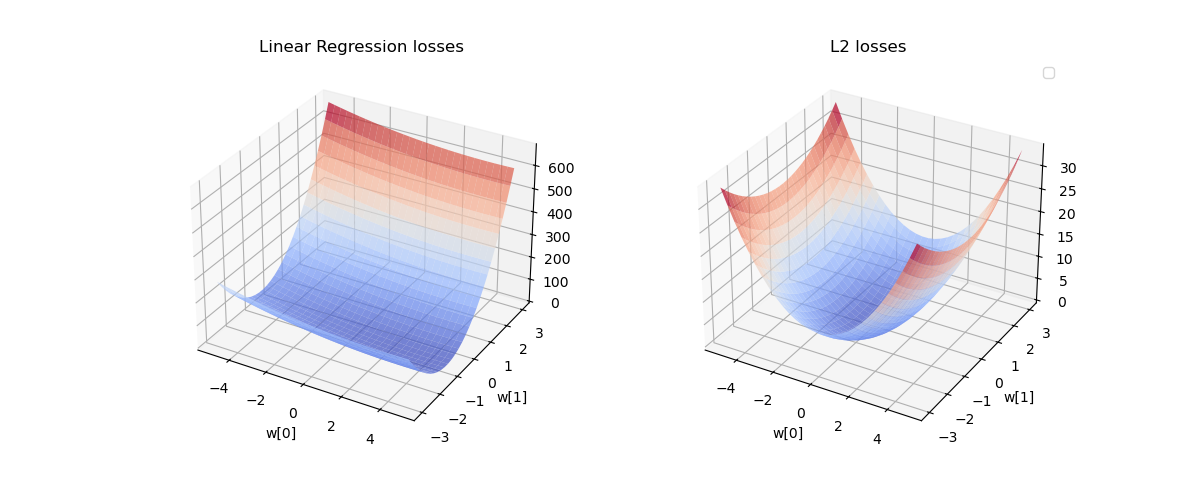
Increasing lambda suppresses parameter values. Can be a gift or a curse depending on your preprocessing, data, and models:
$\lambda = 0$
$\lambda = 50$
$\lambda = 1000$
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# Set seed for reproducibility
np.random.seed(42)
# Generate synthetic dataset
N = 10
x = np.linspace(-10, 10, N)
def f(x):
return -1 * x + 2
random_spikes = np.zeros(N)
random_spikes[8] = 10
t = f(x) + np.random.normal(0, 2.0, size=len(x)) + random_spikes
# Define grid of m0 and m1 values
m0_vals = np.linspace(-5, 5, 30) # Reduced resolution for efficiency
m1_vals = np.linspace(-3, 3, 30)
M0, M1 = np.meshgrid(m0_vals, m1_vals)
# Compute loss for each (m0, m1) pair efficiently
losses = np.zeros_like(M0)
L2_losses = np.zeros_like(M0)
lambda_reg = 1 # Regularization strength
for i in range(M0.shape[0]):
for j in range(M0.shape[1]):
y_pred = M1[i, j] * x + M0[i, j]
loss = np.mean((y_pred - t) ** 2) + lambda_reg * (M0[i, j]**2 + M1[i, j]**2)
losses[i, j] = np.mean((y_pred - t) ** 2)
L2_losses[i, j] = (M0[i, j]**2 + M1[i, j]**2)
# Plot 3D surface
fig = plt.figure(figsize=(12, 5))
# Plot standard least squares loss
ax1 = fig.add_subplot(121, projection='3d')
ax1.plot_surface(M0, M1, losses, cmap='coolwarm', alpha=0.7)
ax1.set_xlabel('w[0]')
ax1.set_ylabel('w[1]')
ax1.set_title('Linear Regression losses')
# Ridge regression plot
ax2 = fig.add_subplot(122, projection='3d')
ax2.plot_surface(M0, M1, L2_losses, cmap='coolwarm', alpha=0.7)
ax2.set_xlabel('w[0]')
ax2.set_ylabel('w[1]')
ax2.set_title('L2 losses')
plt.legend()
plt.savefig("./img/losses_surf")
/var/folders/dl/klptcn0j6cz_5lxgh6mxyd_r0000gn/T/ipykernel_72388/3509197299.py:54: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument. plt.legend()

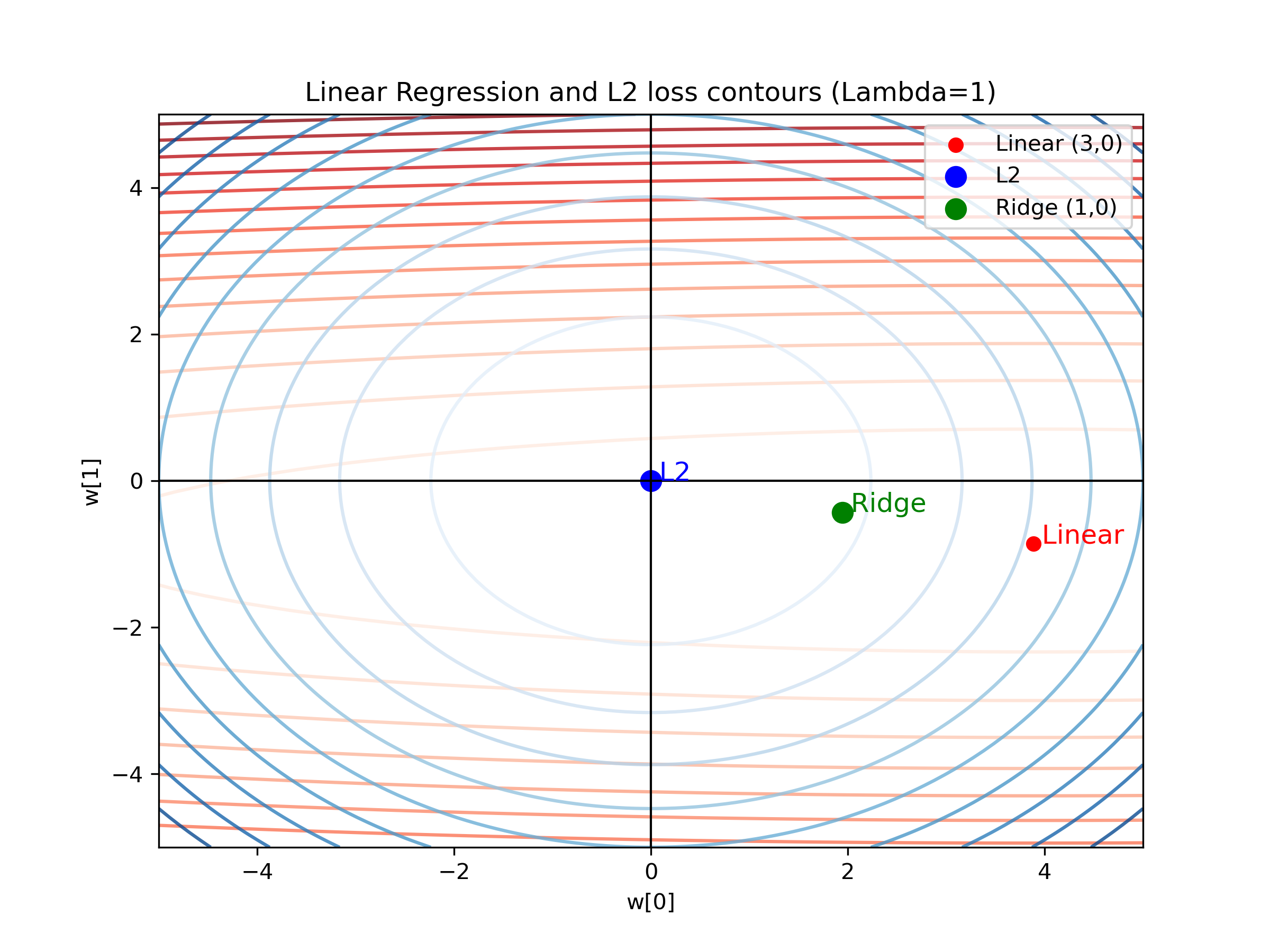
import numpy as np
import matplotlib.pyplot as plt
# Set seed for reproducibility
np.random.seed(42)
# Generate synthetic dataset
N = 10
x = np.linspace(-10, 10, N)
def f(x):
return -1 * x + 2
random_spikes = np.zeros(N)
random_spikes[8] = 10
t = f(x) + np.random.normal(0, 2.0, size=len(x)) + random_spikes
# Define grid of m0 and m1 values
m0_vals = np.linspace(-5, 5, 100) # Wider range for better visualization
m1_vals = np.linspace(-5, 5, 100)
M0, M1 = np.meshgrid(m0_vals, m1_vals)
# Compute loss for each (m0, m1) pair efficiently
losses = np.zeros_like(M0)
L2_losses = np.zeros_like(M0)
lambda_reg = 1 # Regularization strength
for i in range(M0.shape[0]):
for j in range(M0.shape[1]):
y_pred = M1[i, j] * x + M0[i, j]
losses[i, j] = np.mean((y_pred - t) ** 2)
L2_losses[i, j] = (M0[i, j]**2 + M1[i, j]**2)
# Find min points
min_idx = np.unravel_index(np.argmin(losses), losses.shape)
min_m0, min_m1 = M0[min_idx], M1[min_idx]
ridge_m0 = min_m0 / (1 + lambda_reg)
ridge_m1 = min_m1 / (1 + lambda_reg)
# Create Contour Plot
fig, ax = plt.subplots(figsize=(8, 6))
# Plot MSE Loss Contours (Red)
contour1 = ax.contour(M0, M1, losses, levels=15, cmap="Reds", alpha=0.8)
ax.scatter(min_m0, min_m1, color='red', label=f'Linear ({int(min_m0)},{int(min_m1)})')
# Plot L2 Regularization Loss Contours (Blue)
contour2 = ax.contour(M0, M1, L2_losses, levels=10, cmap="Blues", alpha=0.8)
ax.scatter(0, 0, color='blue', label="L2", marker='o', s=80)
# Ridge Regression Min Point
ax.scatter(ridge_m0, ridge_m1, color='green', label=f'Ridge ({int(ridge_m0)},{int(ridge_m1)})', s=80)
# Labels and Formatting
ax.axhline(0, color='black', linewidth=1) # x-axis
ax.axvline(0, color='black', linewidth=1) # y-axis
ax.set_xlabel("w[0]")
ax.set_ylabel("w[1]")
ax.set_title(f"Linear Regression and L2 loss contours (Lambda={lambda_reg})")
# Annotate
ax.text(min_m0, min_m1, " Linear", color='red', fontsize=12)
ax.text(ridge_m0, ridge_m1, " Ridge", color='green', fontsize=12)
ax.text(0, 0, " L2", color='blue', fontsize=12)
# Legend
ax.legend()
# Save and Show
#plt.savefig("./img/losses_contours.png", dpi=300)
plt.show()

Next time we'll talk about the limits of linear regression and more about logistic regression.
[1] Roger Grosse CSC321 lectures - https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/ [2] Freindly ML Tutorial - Linear regression with regularization - https://aunnnn.github.io/ml-tutorial/html/blog_content/linear_regression/linear_regression_regularized.html