In this lecture:
- Continuing discussing the basic structure of the transformer model
- Talk about attention and how it works
Attention is all you need¶
In 2017, Ashish Vaswani and his colleagues at Google Research/Brain published their seminal work "Attention is all you need" [2]. In it, they introduce the transformer architecture which has become the foundation of every large language model since. So in this lecture, let's go through and try to decipher this architecture:
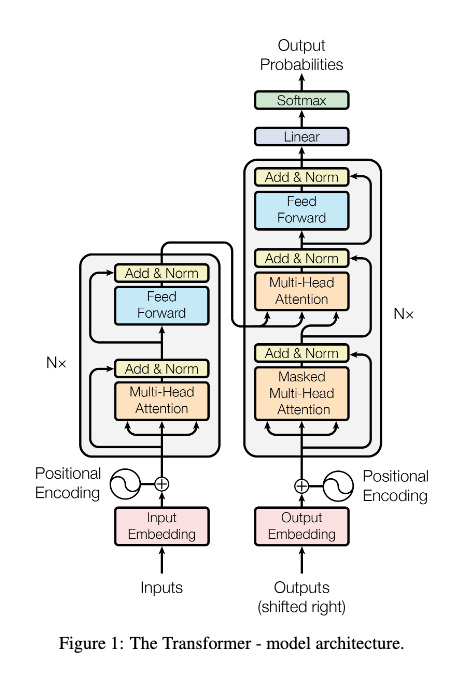
Step 1: Tokenization¶
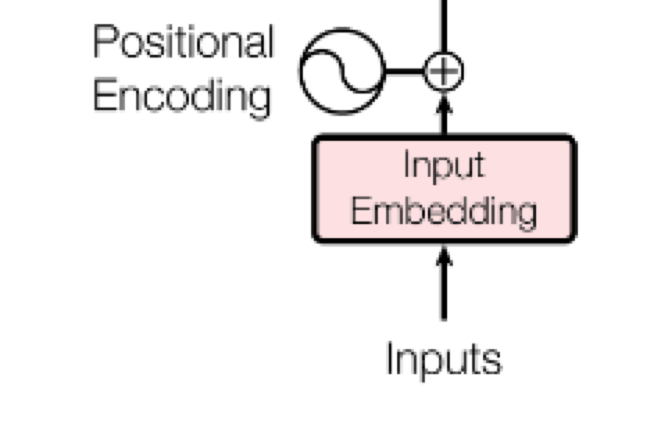
Step 2: Positional encoding¶
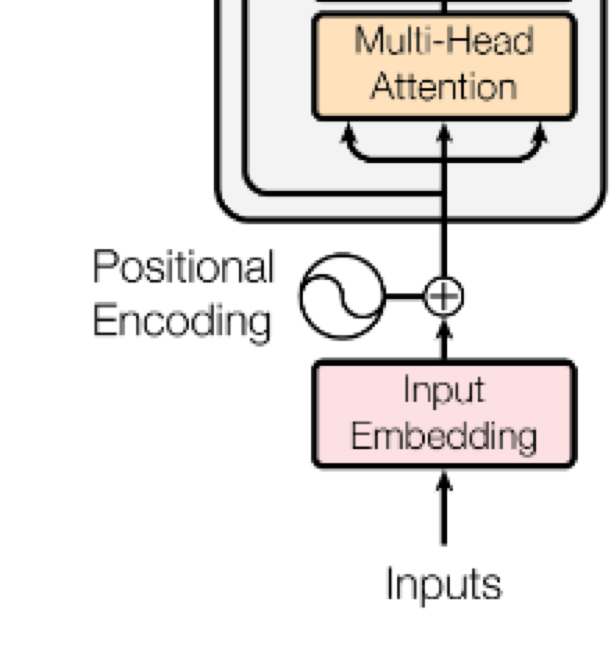
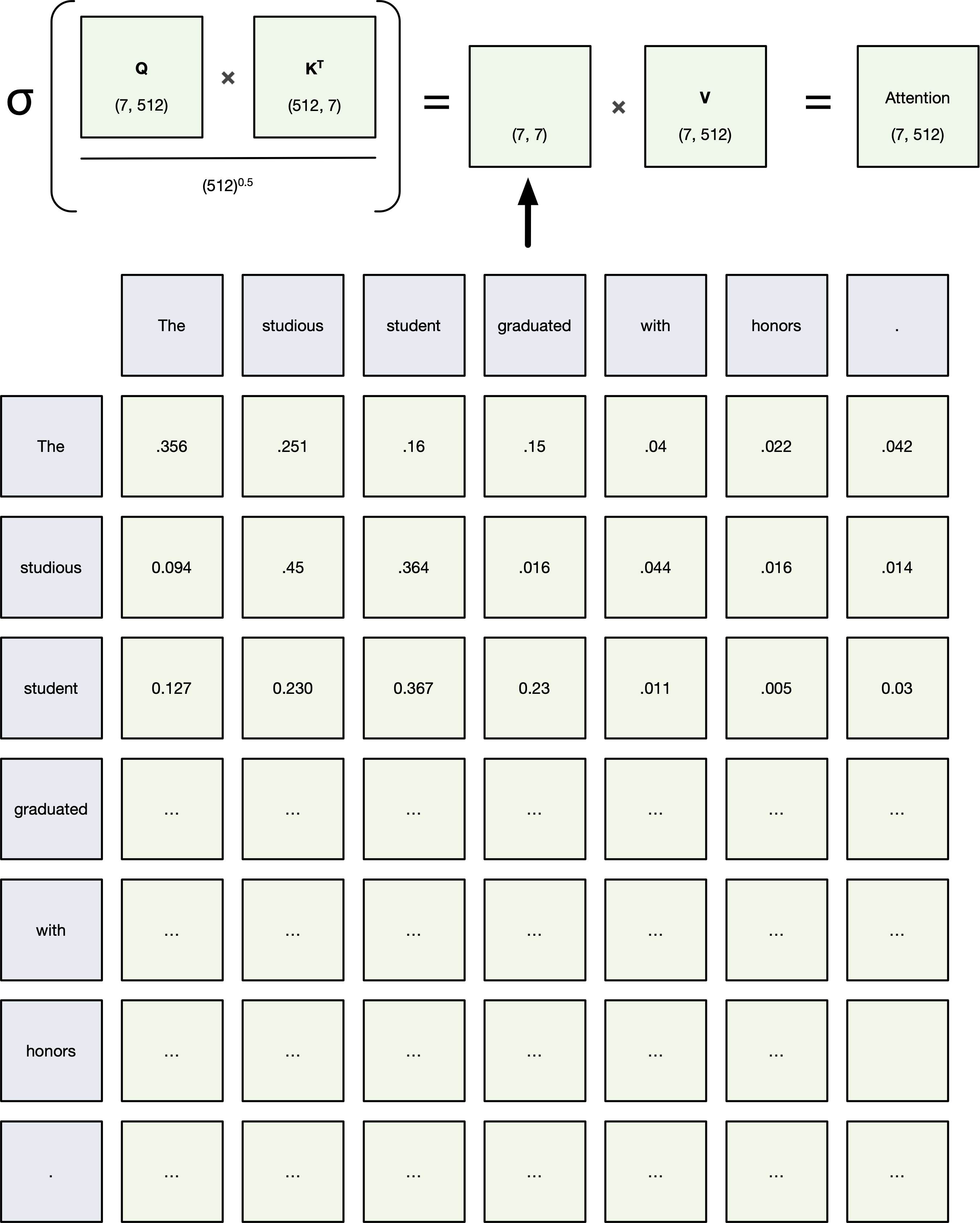
Attention is a mechanism that allows the model to focus on different parts of the input when producing each output.
In the original transformer paper [1], Scaled Dot-Product Attention is used:
Given:
- Query vector: $Q$
- Key vector: $K$
- Value vector: $V$
the attention output is:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d_k}} \right) V $$Key Steps:¶
Compute Scores:
Measure similarity between Query ($Q$) and Key ($K$) by dot product: $QK^\top$Scale Scores:
Divide by $\sqrt{d_k}$ (dimension of keys) to prevent extremely large values.Apply Softmax:
Convert scores into probabilities that sum to 1.Weighted Sum:
Multiply softmax weights by the Values ($V$).
Intuition:¶
- Query asks: "What am I related to?"
- Keys tell: "What components of the sequence are relevant to the duery?"
- Values deliver: "Let's add add relevant words together so each vector contains the orginal word embedding values plus information about the relevant words near it."
Example of self-attention¶
from transformers import AutoTokenizer, AutoModel
import torch
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Correct model
tokenizer = AutoTokenizer.from_pretrained("nreimers/MiniLM-L6-H384-uncased")
model = AutoModel.from_pretrained("nreimers/MiniLM-L6-H384-uncased", output_attentions=True)
# Tokenize input
text = "The studious student graduated with honors."
inputs = tokenizer(text, return_tensors="pt")
# Forward pass
outputs = model(**inputs, output_attentions=True)
attentions = outputs.attentions
# Pick a layer and head
layer_idx = 0
head_idx = 0
attention_matrix = attentions[layer_idx][0, head_idx].detach().cpu().numpy()
# Tokens
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
# Make DataFrame
attention_df = pd.DataFrame(attention_matrix, index=tokens, columns=tokens)
# Plot
plt.figure(figsize=(10,8))
ax = sns.heatmap(attention_df, annot=True, fmt=".2f", cmap="Blues", cbar=False, square=True)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
ax.set_yticklabels(ax.get_yticklabels(), rotation=0)
ax.xaxis.tick_top()
ax.xaxis.set_label_position('top')
plt.title(f"MiniLM Attention (Layer {layer_idx}, Head {head_idx})", pad=20)
plt.tight_layout()
plt.show()
BertSdpaSelfAttention is used but `torch.nn.functional.scaled_dot_product_attention` does not support non-absolute `position_embedding_type` or `output_attentions=True` or `head_mask`. Falling back to the manual attention implementation, but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.

Some notes about attention:¶
We expect the values along the diagonal to be the largest (because a word is most relevant to itself)
Up until now we've used no parameters (though that's about to change)
What are
[CLS]and[SEP]tokens?
| Token | Stands for | Meaning |
|---|---|---|
[CLS] |
Classification token | Special token added at the beginning of every input sequence. Used to summarize the sentence. |
[SEP] |
Separator token | Special token used to separate different segments (like sentence A and B). Also marks the end of a single sentence. |
Multi-Head Attention¶
Instead of applying a single attention function, Transformers use Multi-Head Attention.
How Multi-Head Attention Works:¶
Project Queries, Keys, and Values into multiple subspaces:
- Each head gets different $Q$, $K$, $V$ through learned linear transformations.
Apply Attention independently in each head.
Concatenate the outputs of all heads.
Final Linear Layer combines the concatenated heads.
Mathematically:¶
For each head:
$$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$Then:
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O $$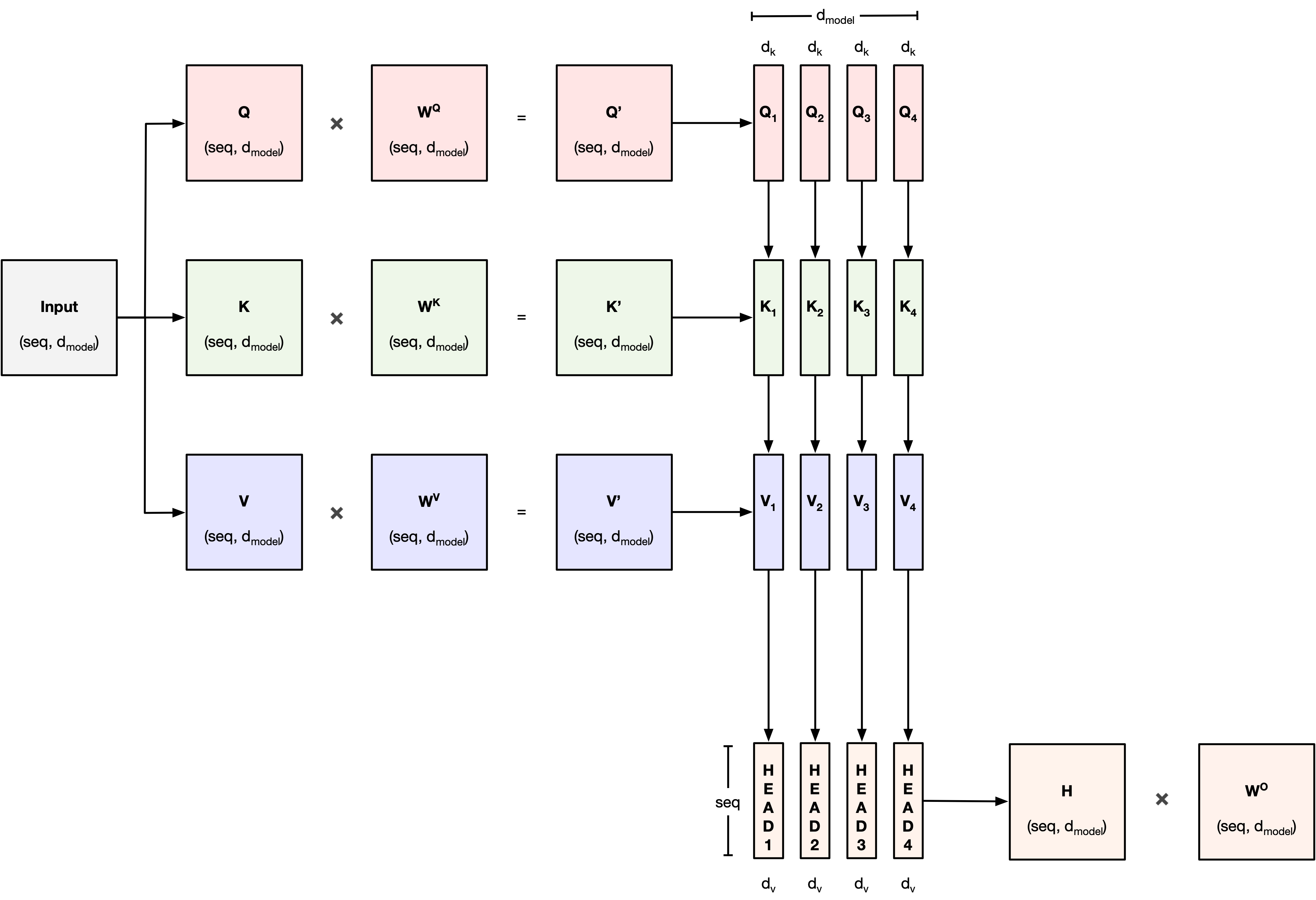
[3]
Example of multi-head attention¶
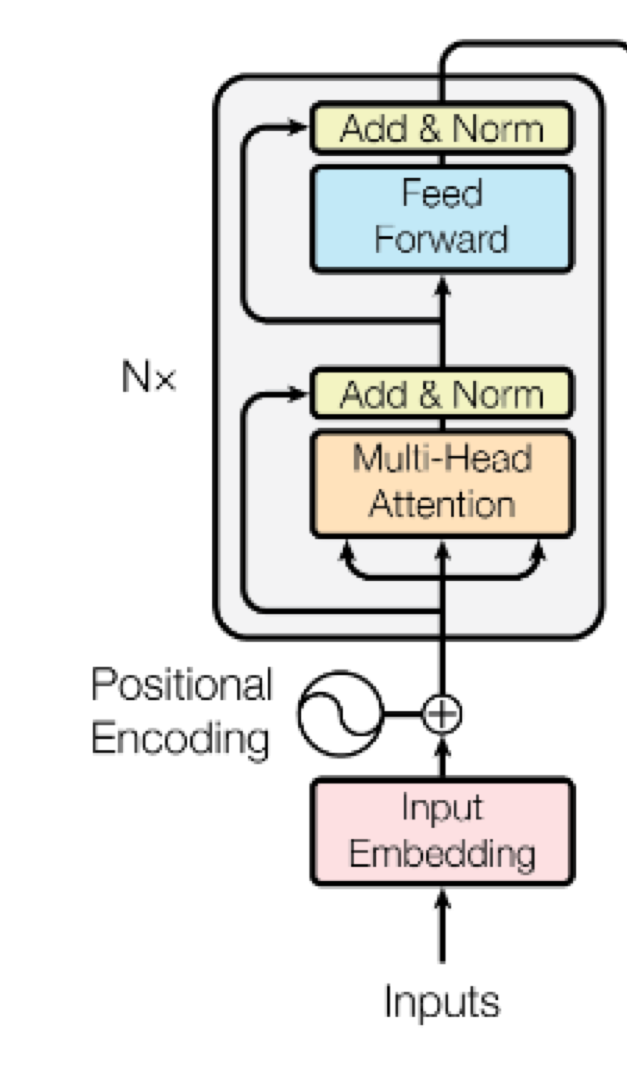
Step 4: Normalize and more Linear layers¶
After the Multi-Head Attention block, the Transformer applies two critical operations:
1. Add & Norm (Residual Connection + Layer Normalization)¶
Residual Connection:
- Adds the original input of the attention block to its output.
Layer Normalization:
- Normalizes across feature dimensions to stabilize and accelerate training.
Helps prevent vanishing/exploding gradients.
Allows smoother gradient flow through the network.
2. Position-wise Feed-Forward Network (FFN)¶
Applies the same small MLP to each token individually.
$$ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $$- $W_1$, $W_2$ are weight matrices.
- First linear layer expands the dimension (e.g., from $d_{\text{model}}$ to 4×$d_{\text{model}}$).
- ReLU non-linearity.
- Second linear layer projects back to $d_{\text{model}}$.
Introduces non-linearity and richer transformations.
Same FFN weights are shared across all sequence positions.
Decoder¶
We have seen the components of the decoder but there are a few subtle variations:
- Masked attention
- Un-equal Q,K,V matrices
Masked Multi-Head Attention¶
Masked Multi-Head Attention is used in the Transformer decoder to prevent attending to future tokens during training.
Purpose:¶
- During training, the model should only use known (past) tokens to predict the next token.
- It must not "cheat" by looking ahead at future tokens.
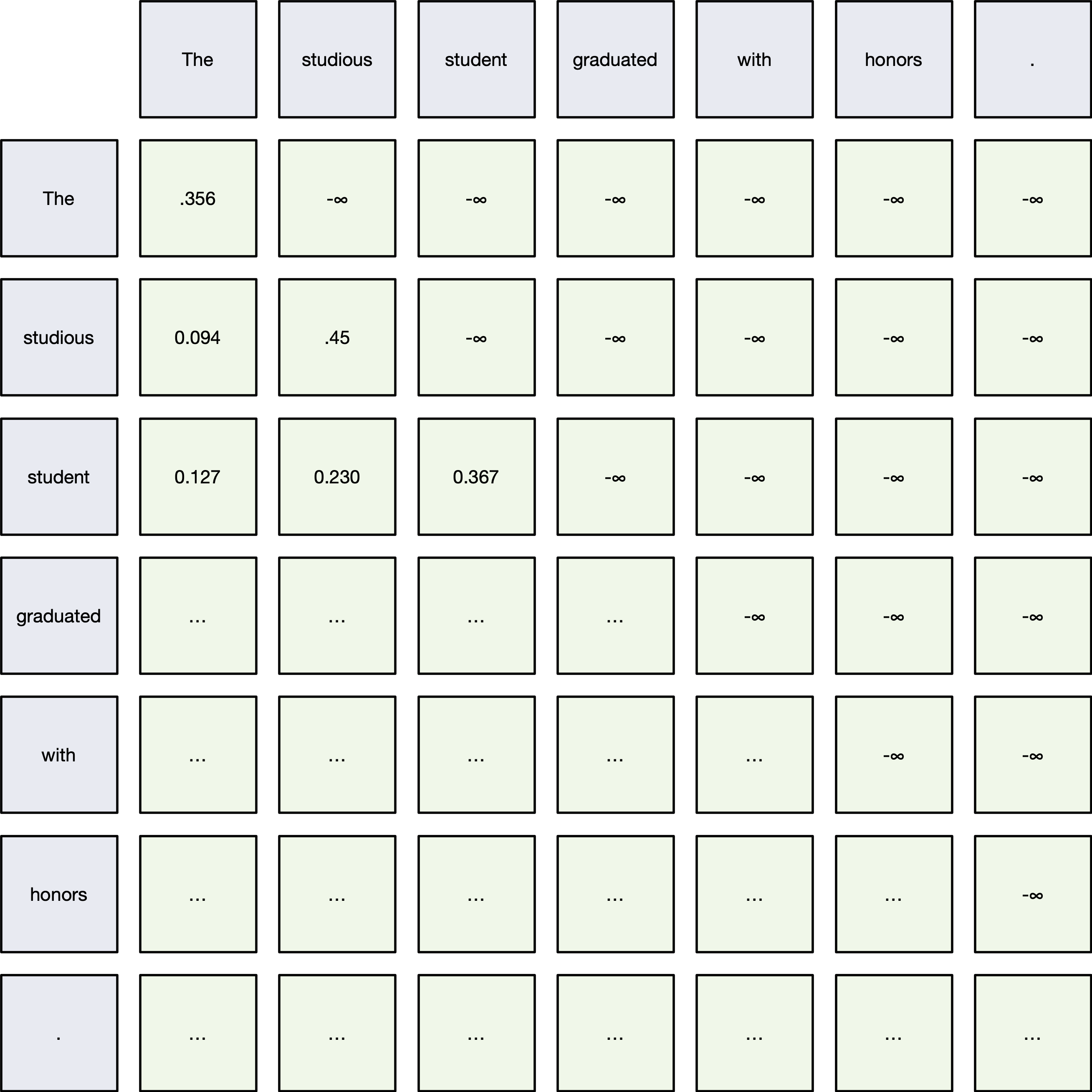
How It Works:¶
- Before applying the softmax to the attention scores $QK^\top$,
- Mask out (set to $-\infty$) all connections to future tokens.
- After masking:
- Softmax assigns zero probability to any future token.
Mathematically:¶
$$ \text{MaskedAttention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top + M}{\sqrt{d_k}} \right)V $$Where:
- $M$ = Mask matrix:
- $0$ for allowed connections (past and current tokens),
- $-\infty$ for disallowed (future tokens).
import torch
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from transformers import AutoTokenizer, AutoModelForCausalLM
# Step 1: Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2", output_attentions=True)
# Step 2: Tokenize input
text = "The studious student graduated with honors."
inputs = tokenizer(text, return_tensors="pt")
# Step 3: Forward pass to get attentions
outputs = model(**inputs, output_attentions=True)
attentions = outputs.attentions
# Step 4: Select layer and head
layer_idx = 0
head_idx = 0
attention_matrix = attentions[layer_idx][0, head_idx].detach().cpu().numpy()
# Step 5: Decode tokens
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
# Step 6: Build square dataframe
attention_df = pd.DataFrame(attention_matrix, index=tokens, columns=tokens)
# Step 7: Plot without offset
plt.figure(figsize=(10, 8))
ax = sns.heatmap(attention_df, annot=True, fmt=".2f", cmap="Greens", cbar=False, square=True)
# Fix the ticks so row and column labels align
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
ax.set_yticklabels(ax.get_yticklabels(), rotation=0)
# Move x-axis labels to the top
ax.xaxis.tick_top()
ax.xaxis.set_label_position('top')
plt.title(f"Attention Matrix - Layer {layer_idx} Head {head_idx}", pad=20)
plt.tight_layout()
plt.show()
--------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) Cell In[14], line 3 1 import torch 2 import matplotlib.pyplot as plt ----> 3 import pandas as pd 4 import seaborn as sns 5 from transformers import AutoTokenizer, AutoModelForCausalLM ModuleNotFoundError: No module named 'pandas'
# This will be useful later:
print(f"Number of layers: {len(model.transformer.h)}")
print(f"Number of attention heads per layer: {model.config.n_head}")
Number of layers: 6 Number of attention heads per layer: 12
Cross-Attention in Transformer Decoder¶
Cross-Attention connects the decoder to the encoder outputs.
Purpose:¶
- Enables the decoder to attend to the full encoded input sequence.
- Essential for sequence-to-sequence tasks (e.g., translation, summarization).
- Allows the decoder to gather relevant information from the source input at every step.
How It Works:¶
- Queries ($Q$) come from the decoder's previous layer.
- Keys ($K$) and Values ($V$) come from the encoder outputs (fixed).
Thus:
$$ \text{CrossAttention}(Q_{\text{decoder}}, K_{\text{encoder}}, V_{\text{encoder}}) $$Full Step-by-Step:¶
- Input: Decoder hidden states (as queries), Encoder outputs (as keys and values).
- Compute Attention Scores: Compare decoder queries with encoder keys.
- Softmax over Scores: Determine relevance of each encoder token to the current decoder token.
- Weighted Sum of Encoder Values: Aggregate useful information from the encoder.
Training¶
Training a Transformer model involves teaching it to predict outputs from inputs using supervised learning.
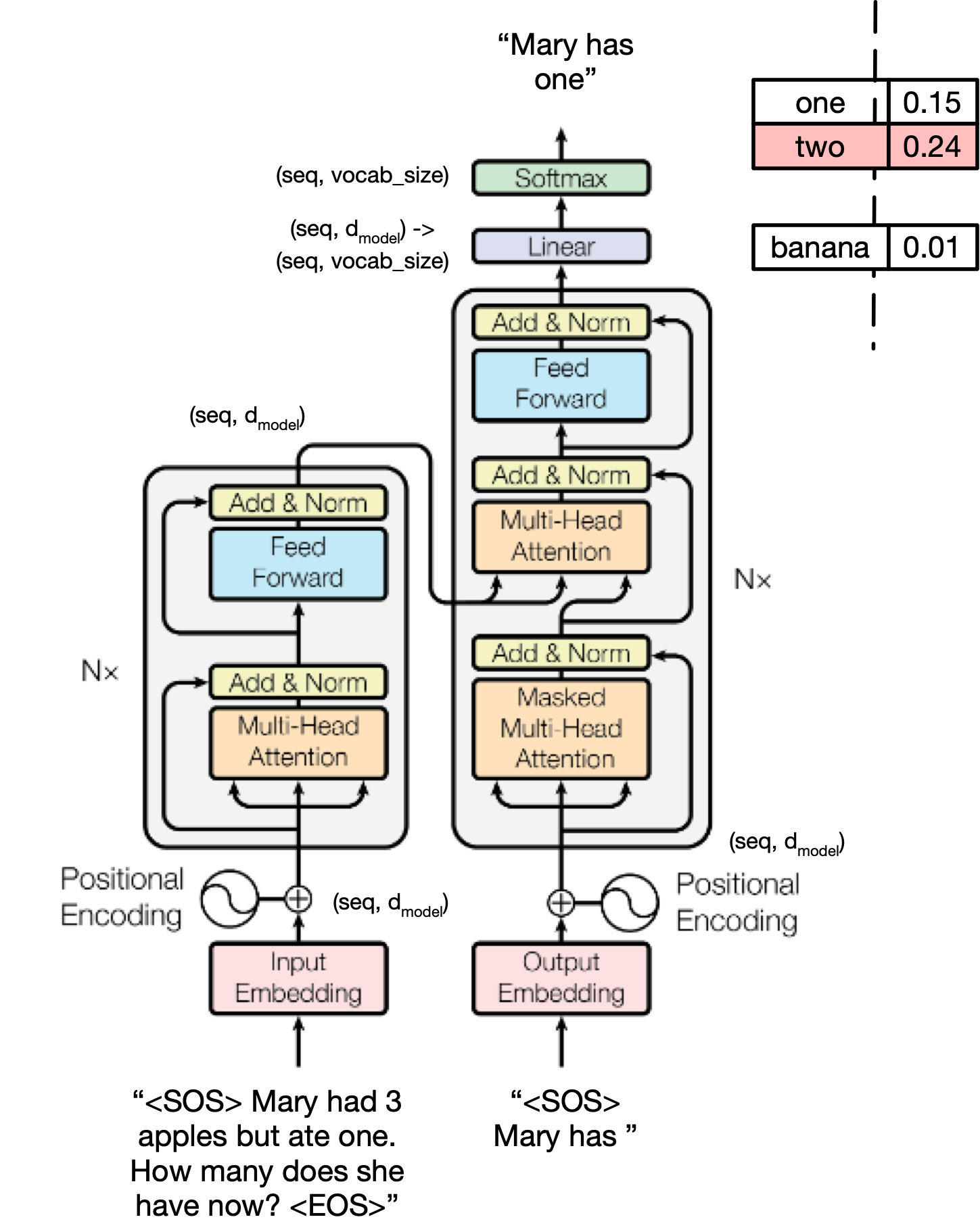
Core Idea:¶
- The Transformer learns to minimize a loss function that measures the difference between its predicted outputs and the ground-truth targets.
- Training is done end-to-end with gradient descent.
🚀 Training Steps:¶
Input Preparation:
- Encoder receives the input sequence (e.g., source sentence).
- Decoder receives the target sequence shifted right (teacher forcing).
Forward Pass:
- Encoder outputs hidden states.
- Decoder generates predictions token-by-token, attending to encoder outputs (via cross-attention).
Loss Computation:
- Compare decoder predictions to ground truth using a loss function, typically cross-entropy loss.
Backward Pass:
- Compute gradients of the loss with respect to all model parameters (weights).
- Backpropagate through attention, feed-forward layers, etc.
Parameter Update:
- Use an optimizer (e.g., Adam) to update parameters based on gradients.
That's it for today¶
- HW10 (last HW!) has been released (due Monday).
- MT2 is a week from Thursday
References¶
[1] Bengio, Yoshua, Patrice Simard, and Paolo Frasconi. "Learning long-term dependencies with gradient descent is difficult." IEEE transactions on neural networks 5.2 (1994): 157-166.
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[3] Umar Jamil "Attention is all you need (Transformer) - Model explanation (including math), Inference and Training" - https://www.youtube.com/watch?v=bCz4OMemCcA
[4] 3Blue1Brown "Attention in transformers, step-by-step | DL6" https://www.youtube.com/watch?v=eMlx5fFNoYc