In this lecture:
- Beam search
- Special tokens
- Bidirectional transformers
- Multi-layer transformer networks
- BERT
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load a tiny GPT-2 model (small enough for CPU)
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
# Make sure model is in eval mode
model.eval()
/Users/nickvashkani/anaconda3/envs/ece364_oldnb_rise/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-5): 6 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)
Language generation - Beam search¶
Let's say we want to generate text. We can imagine the text generation process as choosign between leaves of a tree:

Last time we found the optimal path using greedy selections:

But is that the optimal result? Seems like there ar eleaves with lowere probabilities that the greedy approach misses?
What if we kept track of the the top-k possibilities at every iteration?

This is called beam search.
import torch
from graphviz import Digraph
def beam_search_tree(
model, tokenizer, input_text, beam_width=3, depth=2, device='cpu'
):
model.eval()
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
beams = [(0.0, input_ids, input_text)]
graph = Digraph(format='png')
node_id = 0
def add_node(label):
nonlocal node_id
curr_id = f"n{node_id}"
graph.node(curr_id, label)
node_id += 1
return curr_id
# Add root
root_id = add_node(input_text)
nodes = [(root_id, 0.0, input_ids, input_text)]
for d in range(depth):
new_nodes = []
for parent_id, log_prob_sum, beam_ids, beam_text in nodes:
with torch.no_grad():
outputs = model(beam_ids)
logits = outputs.logits
next_token_logits = logits[:, -1, :]
probs = torch.log_softmax(next_token_logits, dim=-1)
topk_log_probs, topk_indices = torch.topk(probs, beam_width)
for i in range(beam_width):
new_token_id = topk_indices[0, i].unsqueeze(0).unsqueeze(0)
new_log_prob = topk_log_probs[0, i].item()
new_beam_ids = torch.cat([beam_ids, new_token_id], dim=1)
decoded_token = tokenizer.decode(new_token_id[0])
new_text = beam_text + decoded_token
new_score = log_prob_sum + new_log_prob
child_id = add_node(decoded_token)
graph.edge(parent_id, child_id, label=f"{new_score:.2f}")
new_nodes.append((child_id, new_score, new_beam_ids, new_text))
nodes = new_nodes
return graph
start_text = "The meaning of life is to"
g = beam_search_tree(model, tokenizer, start_text, beam_width=3, depth=3)
g.render("./img/beam_search_tree", view=True)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false) huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
'img/beam_search_tree.png'
import torch
import heapq
def beam_search_generate(
model, tokenizer, input_text, beam_width=3, max_length=20, device='cpu', verbose=True
):
"""
Beam search generation from input_text.
Returns top `beam_width` sequences.
"""
model.eval()
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
# Each beam is a tuple: (log_prob_sum, token_ids)
beams = [(0.0, input_ids)]
for step in range(max_length):
new_beams = []
for log_prob_sum, beam_ids in beams:
with torch.no_grad():
outputs = model(beam_ids)
logits = outputs.logits # (1, seq_len, vocab_size)
next_token_logits = logits[:, -1, :] # Only last token
probs = torch.log_softmax(next_token_logits, dim=-1) # Log-probs
# Top-k tokens
topk_log_probs, topk_indices = torch.topk(probs, beam_width)
for i in range(beam_width):
new_token_id = topk_indices[0, i].unsqueeze(0).unsqueeze(0)
new_log_prob = topk_log_probs[0, i].item()
# Append new token and update log probability
new_beam_ids = torch.cat([beam_ids, new_token_id], dim=1)
new_beams.append((log_prob_sum + new_log_prob, new_beam_ids))
# Keep top `beam_width` beams
beams = heapq.nlargest(beam_width, new_beams, key=lambda x: x[0])
if verbose:
print(f"Step {step+1}")
for i, (score, ids) in enumerate(beams):
text = tokenizer.decode(ids[0], skip_special_tokens=True)
print(f"Beam {i+1}: {repr(text)} | log_prob={score:.2f}")
print("\n" + "-"*50 + "\n")
return [
(tokenizer.decode(ids[0], skip_special_tokens=True), score)
for score, ids in beams
]
# Example usage
start_text = "The meaning of life is to"
top_beams = beam_search_generate(model, tokenizer, start_text, beam_width=3, max_length=20)
print("Final Beam Search Results:")
for i, (text, score) in enumerate(top_beams):
print(f"Beam {i+1}: {repr(text)} | log_prob={score:.2f}")
Step 1 Beam 1: 'The meaning of life is to be' | log_prob=-1.34 Beam 2: 'The meaning of life is to live' | log_prob=-3.20 Beam 3: 'The meaning of life is to say' | log_prob=-3.96 -------------------------------------------------- Step 2 Beam 1: 'The meaning of life is to be understood' | log_prob=-4.55 Beam 2: 'The meaning of life is to live in' | log_prob=-4.59 Beam 3: 'The meaning of life is to be able' | log_prob=-4.80 -------------------------------------------------- Step 3 Beam 1: 'The meaning of life is to be able to' | log_prob=-4.82 Beam 2: 'The meaning of life is to live in a' | log_prob=-5.90 Beam 3: 'The meaning of life is to be understood as' | log_prob=-6.04 -------------------------------------------------- Step 4 Beam 1: 'The meaning of life is to be able to be' | log_prob=-6.76 Beam 2: 'The meaning of life is to be able to live' | log_prob=-7.47 Beam 3: 'The meaning of life is to be understood as a' | log_prob=-7.52 -------------------------------------------------- Step 5 Beam 1: 'The meaning of life is to be able to live in' | log_prob=-9.11 Beam 2: 'The meaning of life is to be able to live with' | log_prob=-9.84 Beam 3: 'The meaning of life is to be able to be able' | log_prob=-9.98 -------------------------------------------------- Step 6 Beam 1: 'The meaning of life is to be able to be able to' | log_prob=-10.00 Beam 2: 'The meaning of life is to be able to live in a' | log_prob=-10.36 Beam 3: 'The meaning of life is to be able to live in harmony' | log_prob=-11.04 -------------------------------------------------- Step 7 Beam 1: 'The meaning of life is to be able to live in harmony with' | log_prob=-11.68 Beam 2: 'The meaning of life is to be able to be able to be' | log_prob=-11.73 Beam 3: 'The meaning of life is to be able to be able to live' | log_prob=-12.57 -------------------------------------------------- Step 8 Beam 1: 'The meaning of life is to be able to live in harmony with the' | log_prob=-12.88 Beam 2: 'The meaning of life is to be able to be able to be able' | log_prob=-13.92 Beam 3: 'The meaning of life is to be able to live in harmony with nature' | log_prob=-13.94 -------------------------------------------------- Step 9 Beam 1: 'The meaning of life is to be able to be able to be able to' | log_prob=-13.93 Beam 2: 'The meaning of life is to be able to live in harmony with nature,' | log_prob=-15.20 Beam 3: 'The meaning of life is to be able to live in harmony with nature.' | log_prob=-15.39 -------------------------------------------------- Step 10 Beam 1: 'The meaning of life is to be able to be able to be able to be' | log_prob=-15.05 Beam 2: 'The meaning of life is to be able to be able to be able to live' | log_prob=-16.69 Beam 3: 'The meaning of life is to be able to live in harmony with nature, and' | log_prob=-16.86 -------------------------------------------------- Step 11 Beam 1: 'The meaning of life is to be able to be able to be able to be able' | log_prob=-16.15 Beam 2: 'The meaning of life is to be able to live in harmony with nature, and to' | log_prob=-17.98 Beam 3: 'The meaning of life is to be able to be able to be able to live in' | log_prob=-18.64 -------------------------------------------------- Step 12 Beam 1: 'The meaning of life is to be able to be able to be able to be able to' | log_prob=-16.16 Beam 2: 'The meaning of life is to be able to live in harmony with nature, and to be' | log_prob=-19.31 Beam 3: 'The meaning of life is to be able to be able to be able to live in a' | log_prob=-19.69 -------------------------------------------------- Step 13 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be' | log_prob=-16.77 Beam 2: 'The meaning of life is to be able to be able to be able to be able to live' | log_prob=-19.40 Beam 3: 'The meaning of life is to be able to be able to be able to be able to have' | log_prob=-19.47 -------------------------------------------------- Step 14 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able' | log_prob=-17.25 Beam 2: 'The meaning of life is to be able to be able to be able to be able to have a' | log_prob=-20.80 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be a' | log_prob=-21.25 -------------------------------------------------- Step 15 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to' | log_prob=-17.26 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be a person' | log_prob=-23.25 Beam 3: 'The meaning of life is to be able to be able to be able to be able to have a sense' | log_prob=-23.46 -------------------------------------------------- Step 16 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to be' | log_prob=-17.61 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be able to have' | log_prob=-20.70 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be able to live' | log_prob=-21.11 -------------------------------------------------- Step 17 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to be able' | log_prob=-17.85 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be able to have a' | log_prob=-21.94 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be able to be a' | log_prob=-22.61 -------------------------------------------------- Step 18 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to be able to' | log_prob=-17.86 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be able to be a person' | log_prob=-24.57 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be able to have a life' | log_prob=-24.67 -------------------------------------------------- Step 19 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to be able to be' | log_prob=-18.06 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be able to be able to have' | log_prob=-21.49 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be able to be able to live' | log_prob=-22.31 -------------------------------------------------- Step 20 Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to be able to be able' | log_prob=-18.19 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be able to be able to have a' | log_prob=-22.67 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be able to be able to be a' | log_prob=-23.58 -------------------------------------------------- Final Beam Search Results: Beam 1: 'The meaning of life is to be able to be able to be able to be able to be able to be able to be able' | log_prob=-18.19 Beam 2: 'The meaning of life is to be able to be able to be able to be able to be able to be able to have a' | log_prob=-22.67 Beam 3: 'The meaning of life is to be able to be able to be able to be able to be able to be able to be a' | log_prob=-23.58
we can just use the transformers library and make our lives easier:¶
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
input_text = "The meaning of life is to"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Generate using built-in beam search
beam_output = model.generate(
input_ids,
max_length=10,
num_beams=3,
early_stopping=True,
num_return_sequences=3 # Get top 3 beams
)
# Decode result
for i, output in enumerate(beam_output):
text = tokenizer.decode(output, skip_special_tokens=True)
print(f"Beam {i+1}: {repr(text)}")
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results. Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Beam 1: 'The meaning of life is to be able to be' Beam 2: 'The meaning of life is to be able to live' Beam 3: 'The meaning of life is to be understood as a'
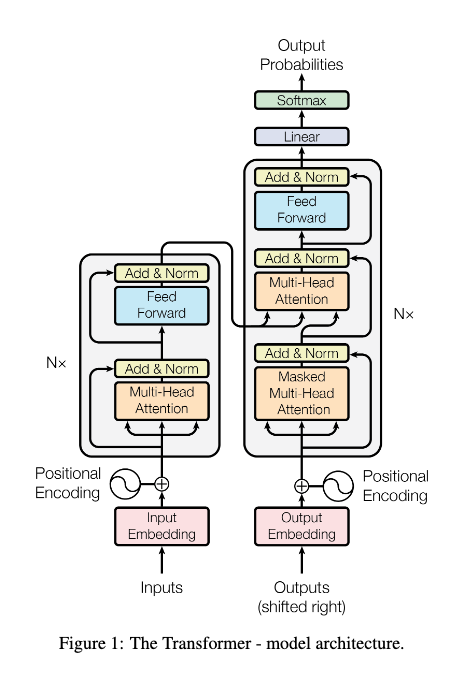
Training¶
Training a Transformer model involves teaching it to predict outputs from inputs using supervised learning.
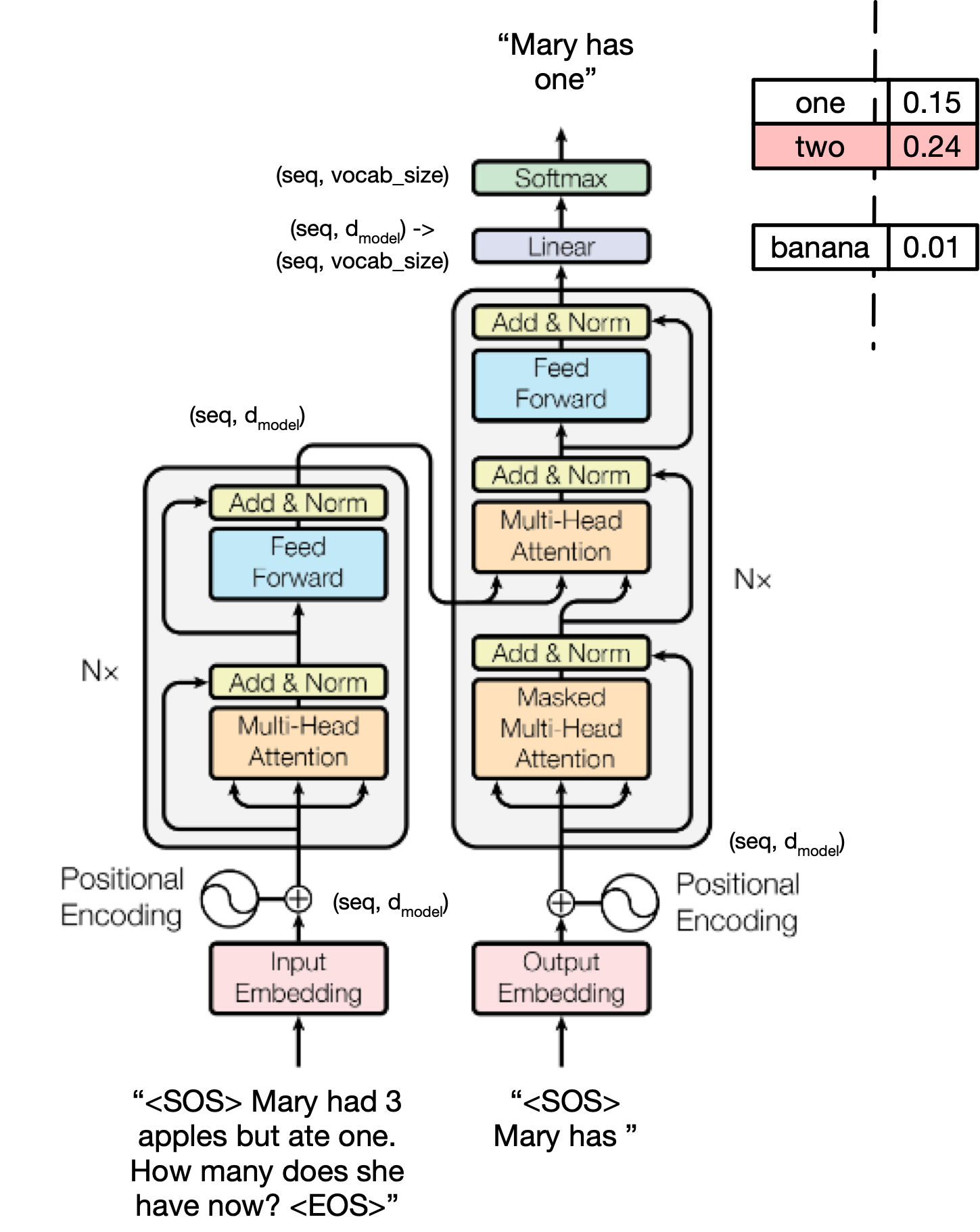
Core Idea:¶
- The Transformer learns to minimize a loss function that measures the difference between its predicted outputs and the ground-truth targets.
- Training is done end-to-end with gradient descent.
🚀 Training Steps:¶
Input Preparation:
- Encoder receives the input sequence (e.g., source sentence).
- Decoder receives the target sequence shifted right (teacher forcing).
Forward Pass:
- Encoder outputs hidden states.
- Decoder generates predictions token-by-token, attending to encoder outputs (via cross-attention).
Loss Computation:
- Compare decoder predictions to ground truth using a loss function, typically cross-entropy loss.
Backward Pass:
- Compute gradients of the loss with respect to all model parameters (weights).
- Backpropagate through attention, feed-forward layers, etc.
Parameter Update:
- Use an optimizer (e.g., Adam) to update parameters based on gradients.
Special tokens¶
Let's look back at the tokenized input from before:
from transformers import AutoTokenizer
# Load model
tokenizer = AutoTokenizer.from_pretrained("nreimers/MiniLM-L6-H384-uncased")
# Input text
text = "The studious student graduated with honors."
# Proper tokenization that adds [CLS] and [SEP]
inputs = tokenizer(text, add_special_tokens=True)
# Convert ids back to readable tokens
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"])
print(tokens)
## btw "inputs = tokenizer.tokenize(text)" doesn't reveal the special tokens. It's mostly just to split words
['[CLS]', 'the', 'studio', '##us', 'student', 'graduated', 'with', 'honors', '.', '[SEP]']
[CLS]? [SEP]? What?¶
What are [CLS] and [SEP] tokens?
| Token | Stands for | Meaning |
|---|---|---|
[CLS] |
Classification token | Special token added at the beginning of every input sequence. Used to summarize the sentence. |
[SEP] |
Separator token | Special token used to separate different segments (like sentence A and B). Also marks the end of a single sentence. |
[CLS] token¶
- Short for "CLaSsification" token.
- Inserted at the start of every input.
- In models like BERT, the final hidden state corresponding to
[CLS]is used as the sentence representation. - Example usage:
- For sentence classification (e.g., spam detection), only the
[CLS]output vector is used for prediction. - For QA tasks,
[CLS]may be used to predict if an answer exists.
- For sentence classification (e.g., spam detection), only the
You can think of
[CLS]as a "summary slot" that captures the overall meaning.
[SEP] token¶
- Short for "Separator" token.
- Inserted between segments (for example, between two sentences).
- Marks the end of a sentence or segment.
- In tasks like Question-Answering, the input might be:
[CLS] Question tokens [SEP] Paragraph tokens [SEP]
[CLS] always at the start?¶
If the [CLS] token always starts a input, why do we inlcude it?
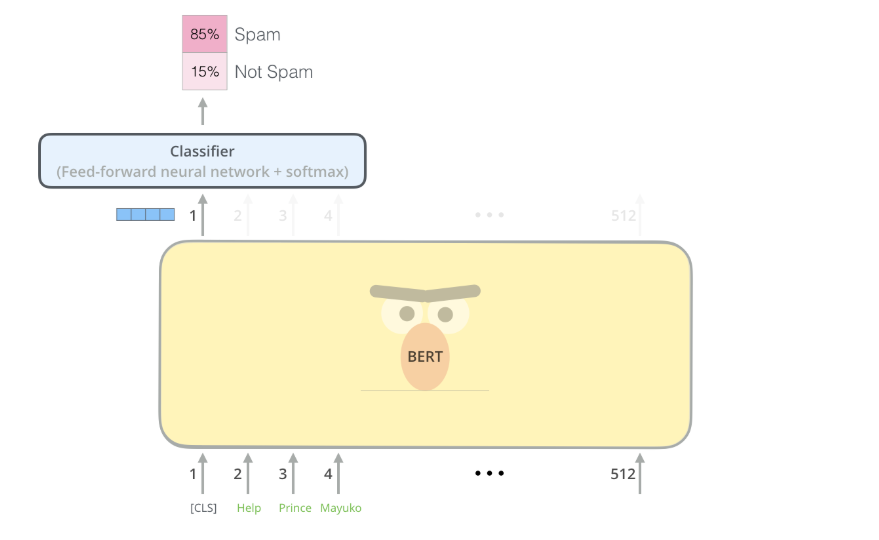 image from [1].
image from [1].
Here's the reason:
| Reason | Why it matters |
|---|---|
| Training Flexibility | During training, the model treats [CLS] as a normal token position — it has an embedding, it has hidden states, etc. It’s not “magic”; it’s learned. |
| Pooling Layer | The final [CLS] hidden state is fed into a classification head (MLP, linear layer, etc.) for tasks like sentence classification. |
| Attention Mechanism | [CLS] participates in self-attention — it can “attend” to other tokens and other tokens can “attend” to [CLS]. The model needs a “collector” node inside attention dynamics. |
| Multi-segment Inputs | If you have two sentences (e.g., Question + Answer), you need [CLS] SentenceA [SEP] SentenceB [SEP]. Without [CLS], it would be ambiguous where to pool for classification. |
| Pretraining / Finetuning Separation | [CLS] allows pretrained models to be flexibly finetuned for different tasks without changing architecture. |
- It has its own embedding.
- It produces its own hidden state.
- It interacts dynamically with attention.
- It becomes a “summary vector” because the model learns to make it one.
Different architectures and tokenizers have different conventions!¶
| Model | Special Tokens Used | ||||||
|---|---|---|---|---|---|---|---|
| BERT | [CLS], [SEP], [PAD], [MASK], [UNK] |
||||||
| RoBERTa | <s>, </s>, <pad>, <mask>, <unk> |
||||||
| GPT-2 | No explicit special tokens by default (but can use `< | bos | >,< |
eos | >,< |
pad | >`) |
| T5 | Uses <pad>, <extra_id_N> masking tokens |
Why Special Tokens Matter:
- Special tokens signal different behavior to the model.
- They enable multitask training: classification, translation, masked prediction, etc.
- They make batch training efficient by padding shorter sequences.
Lots of special tokens¶
There are lots of special tokens commonly used in LLMs.
| Token | Meaning | Usage |
|---|---|---|
[CLS] |
Classification token | Summarizes input for tasks like classification. |
[SEP] |
Separator token | Separates different segments or sentences. |
[PAD] |
Padding token | Fills empty space in a batch so all sequences are the same length. |
[MASK] |
Masking token | Used during training (especially in BERT) to hide tokens for prediction. |
[BOS] |
Beginning Of Sentence | Used in decoder models (e.g., GPT) to mark start of generation. |
[EOS] |
End Of Sentence | Used to mark the end of a sentence or sequence. |
[UNK] |
Unknown token | Used when the tokenizer encounters a word it doesn’t recognize. |
[PAD] |
Padding token | Used to pad sequences to a common length. |
<s> |
Start-of-sequence (T5 / RoBERTa) | Similar to [BOS], but with different tokenization schemes. |
</s> |
End-of-sequence (T5 / RoBERTa) | Similar to [EOS]. |
If they are used depends on the model.
Layers in Transformers¶
Let's think back to recurrent neural networks. There were variations that ahd layers. What did their layer structure look like?
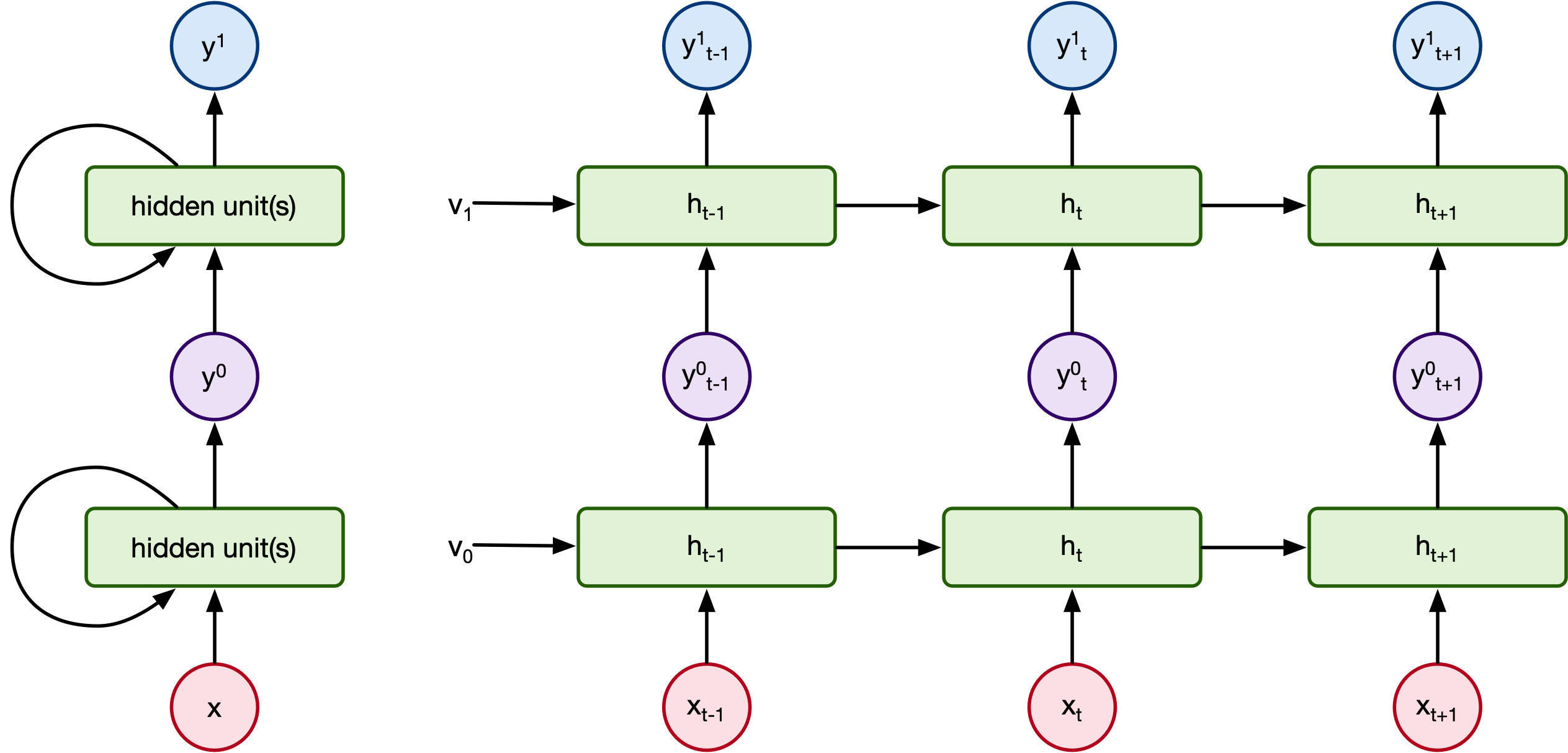
What would a layered transformer network look like?
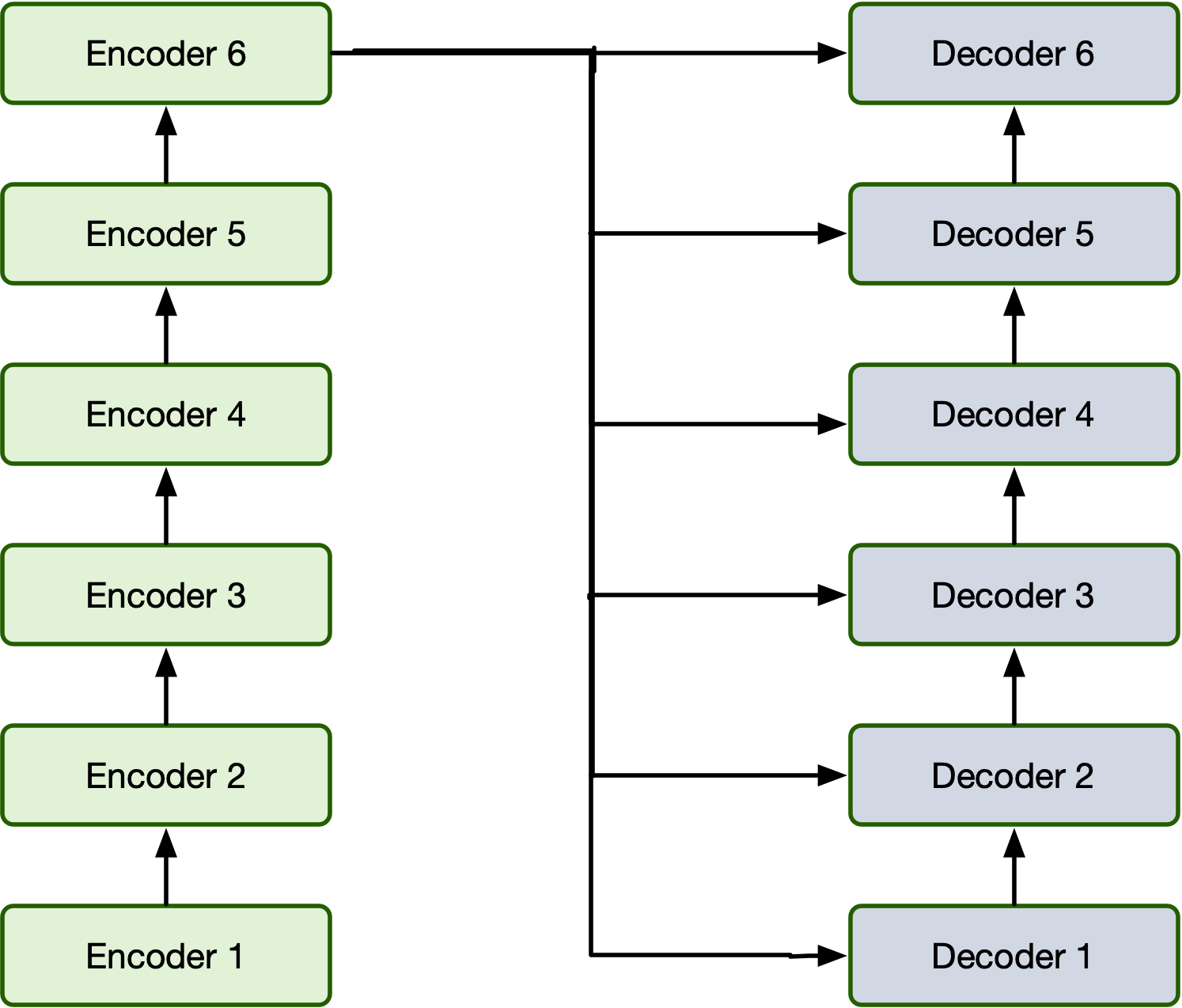
Bidirectionality¶
Remember we have bidirectional RNNs?
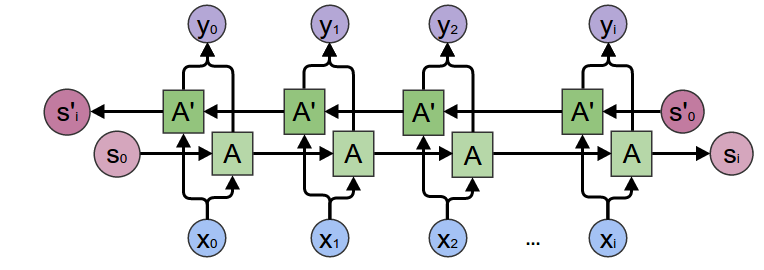
Well all transformers are bidirectional?¶
Bidirectional Encoder Representations from Transformers (BERT) Model [2]¶
BERT is a example of a encoder only architecture:
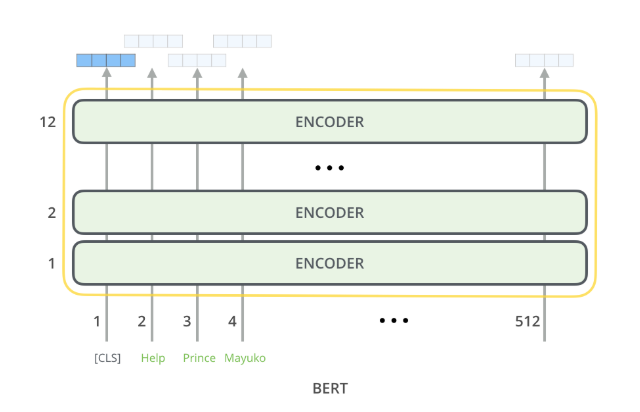 image from [1].
image from [1].
Encoder-Only Characteristics¶
- Input: Takes in the entire sequence of tokens at once (e.g., a sentence or sentence pair).
- Self-Attention: Uses bidirectional self-attention, meaning every token attends to both its left and right context.
- Output: Produces contextualized embeddings for all input tokens simultaneously.
What BERT Doesn’t Do¶
- It does not generate text token-by-token like GPT.
- It does not include a decoder component (unlike GPT or encoder-decoder models like T5).
Language training methods¶
Masked Language Modeling (MLM)¶
- Objective: Predict masked tokens in a sentence using bidirectional context.
- Procedure:
- Randomly select 15% of the tokens:
- 80% → replaced with
[MASK] - 10% → replaced with a random token
- 10% → left unchanged
- 80% → replaced with
- Randomly select 15% of the tokens:
- Example:
Input: "The quick brown [MASK] jumps over the lazy dog." Target: "fox" - Loss: Cross-entropy loss computed only on the masked positions.
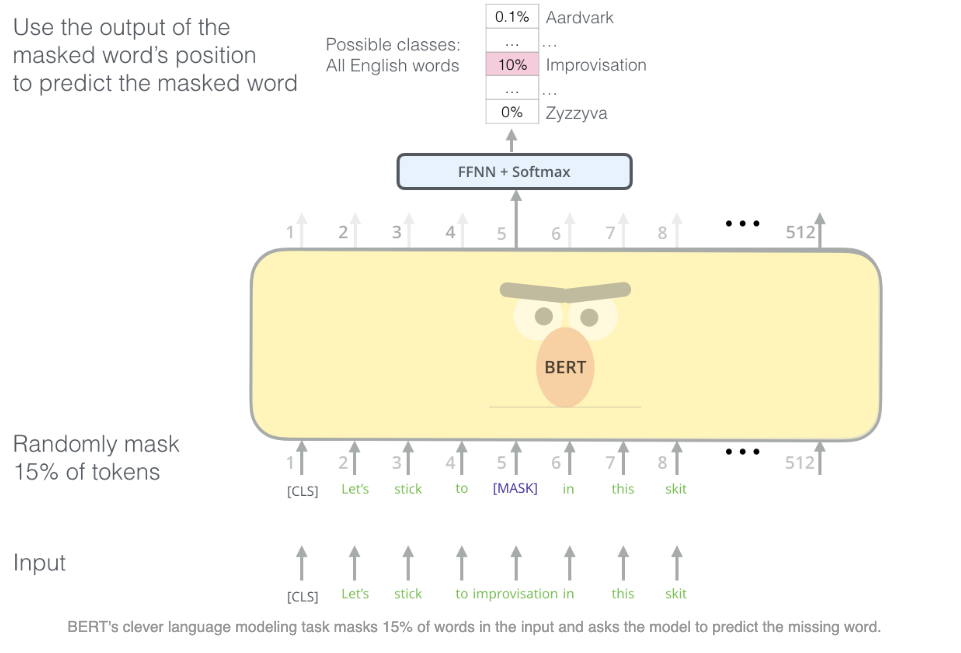 image from [1].
image from [1].
from transformers import BertTokenizer, BertForPreTraining, DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments
from datasets import load_dataset
# Load pretrained tokenizer and model
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForPreTraining.from_pretrained("bert-base-uncased")
# Load small dataset and tokenize
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="train[:1%]") # tiny sample for demo
def tokenize_function(examples):
return tokenizer(examples["text"], return_special_tokens_mask=True, truncation=True, padding="max_length", max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Masking strategy for MLM
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
# Training setup
training_args = TrainingArguments(
output_dir="./bert-pretraining-demo",
overwrite_output_dir=True,
num_train_epochs=1,
per_device_train_batch_size=16,
save_steps=10_000,
save_total_limit=2,
)
# Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator,
)
trainer.train()
Next Sentence Prediction (NSP)¶
- Objective: Predict if Sentence B follows Sentence A in the original document.
- Training Setup:
- 50% of the time: Sentence B is the actual next sentence →
IsNext - 50% of the time: Sentence B is randomly sampled →
NotNext
- 50% of the time: Sentence B is the actual next sentence →
- Example:
Sentence A: "He went to the store." Sentence B: "He bought milk." → IsNext Sentence B: "The Eiffel Tower is in Paris." → NotNext - Loss: Binary classification loss on the
[CLS]token representation.
Input Format¶
[CLS] Sentence A [SEP] Sentence B [SEP]
[CLS]→ Classification token (used for NSP loss)[SEP]→ Separator token between segments- Segment embeddings distinguish Sentence A vs Sentence B
- Positional embeddings help track token order
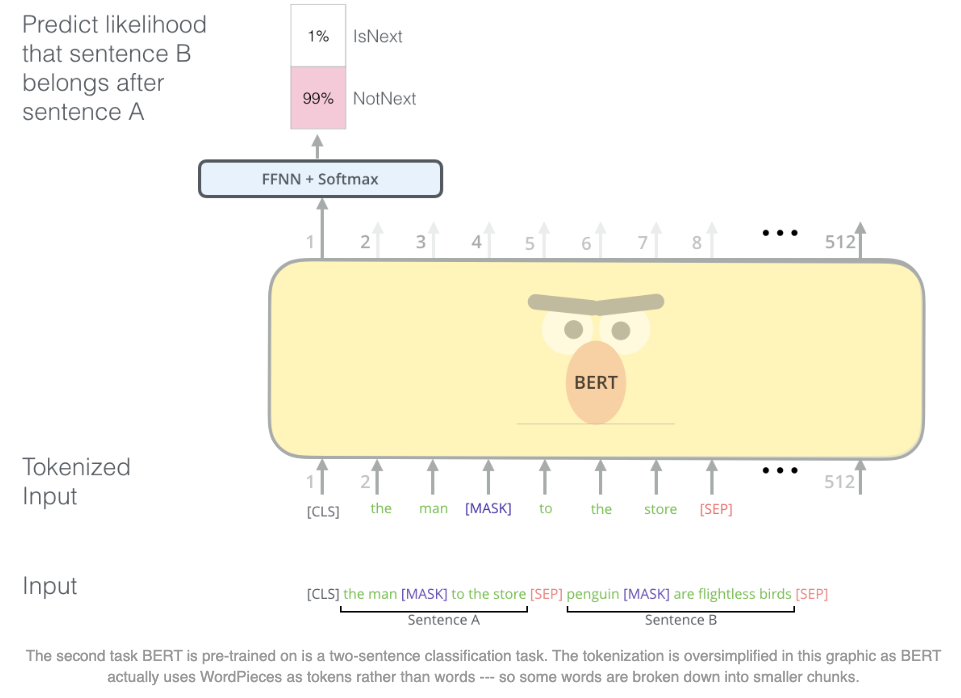 image from [1].
image from [1].
Are transformers are bidirectional?¶
General Purpose Transformer (GPT)¶
A decoder-only model uses just the decoder stack from the original Transformer architecture. A prime example is GPT (e.g., GPT-2, GPT-3, GPT-4).
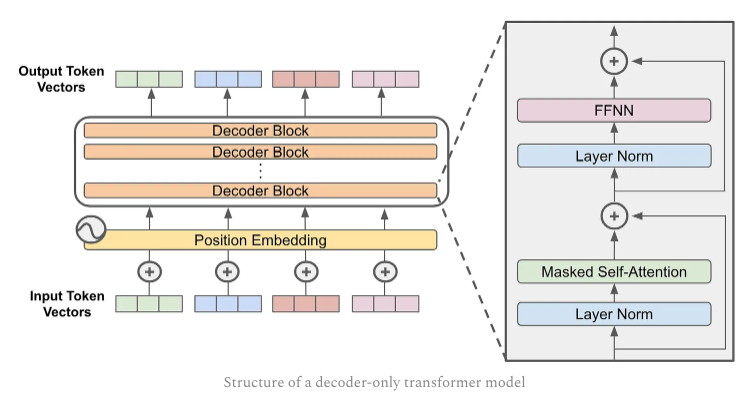 image from [3]
image from [3]
Key Characteristics¶
- Architecture: Only the Transformer decoder is used.
- Causal Masking: The model cannot attend to future tokens — only past tokens.
- Auto-regressive: Generates tokens one at a time, conditioning on previously generated tokens.
What It Lacks¶
- No bidirectional context like BERT.
- No encoder stack, so not ideal for classification or sentence-pair tasks.
Some important models¶
| Model | Encoder | Decoder | Use Case |
|---|---|---|---|
| BERT | ✅ | ❌ | Understanding tasks (e.g., classification, QA) |
| GPT | ❌ | ✅ | Generative tasks (e.g., text generation) |
| T5 | ✅ | ✅ | Seq2Seq tasks (e.g., translation, summarization) |
That's it for today¶
- HW10 is due on Monday.
- Midterm next Thursday.
- Skillset/cheat-sheet will be released by today.
- Give me till the weekend to release the sample. Questions are still in flux so we need a extra day or two.
- And most importantly, have a good weekend.
References¶
[1] Alammar, J. "The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)" - https://jalammar.github.io/illustrated-bert/
[2] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019.
[3] Wolfe, C. "Decoder-Only Transformers: The Workhorse of Generative LLMs" - https://cameronrwolfe.substack.com/p/decoder-only-transformers-the-workhorse
Other transformer resources:¶