In this lecture:
- What we've learned
- Future trends
- The stunning amount there is left to know
Well we've learned a lot in a very short period of time:¶
Foundational tools and methods¶
Python Skills:
- Matrix/Tensor slicing and manipulation
- Views
Math Skills:
- Matrix Calculus
- Linear Algebra
Programming Frameworks
- PyTorch
- NumPy
- Scikit-learn
Optimization Methods:
- Computation graphs
- Primal optimization
- Gradient descent
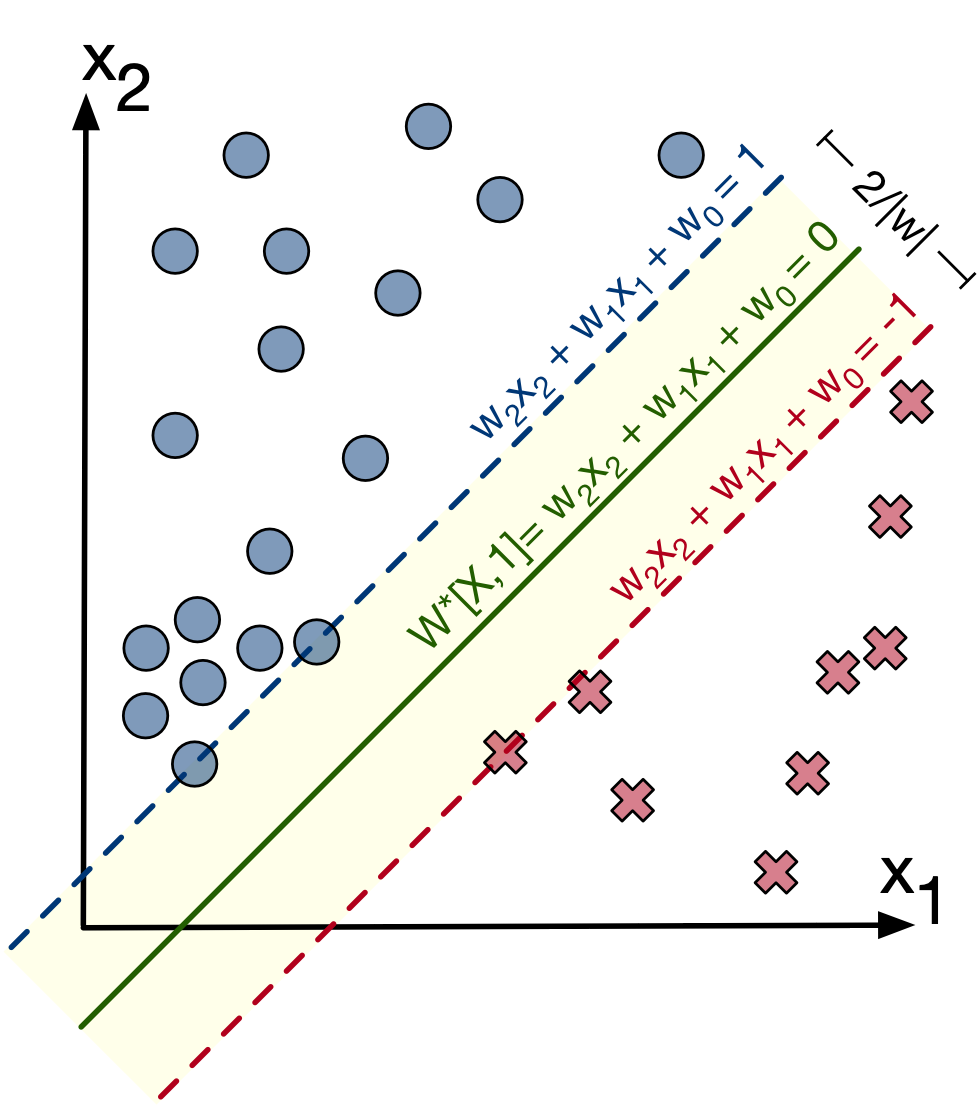
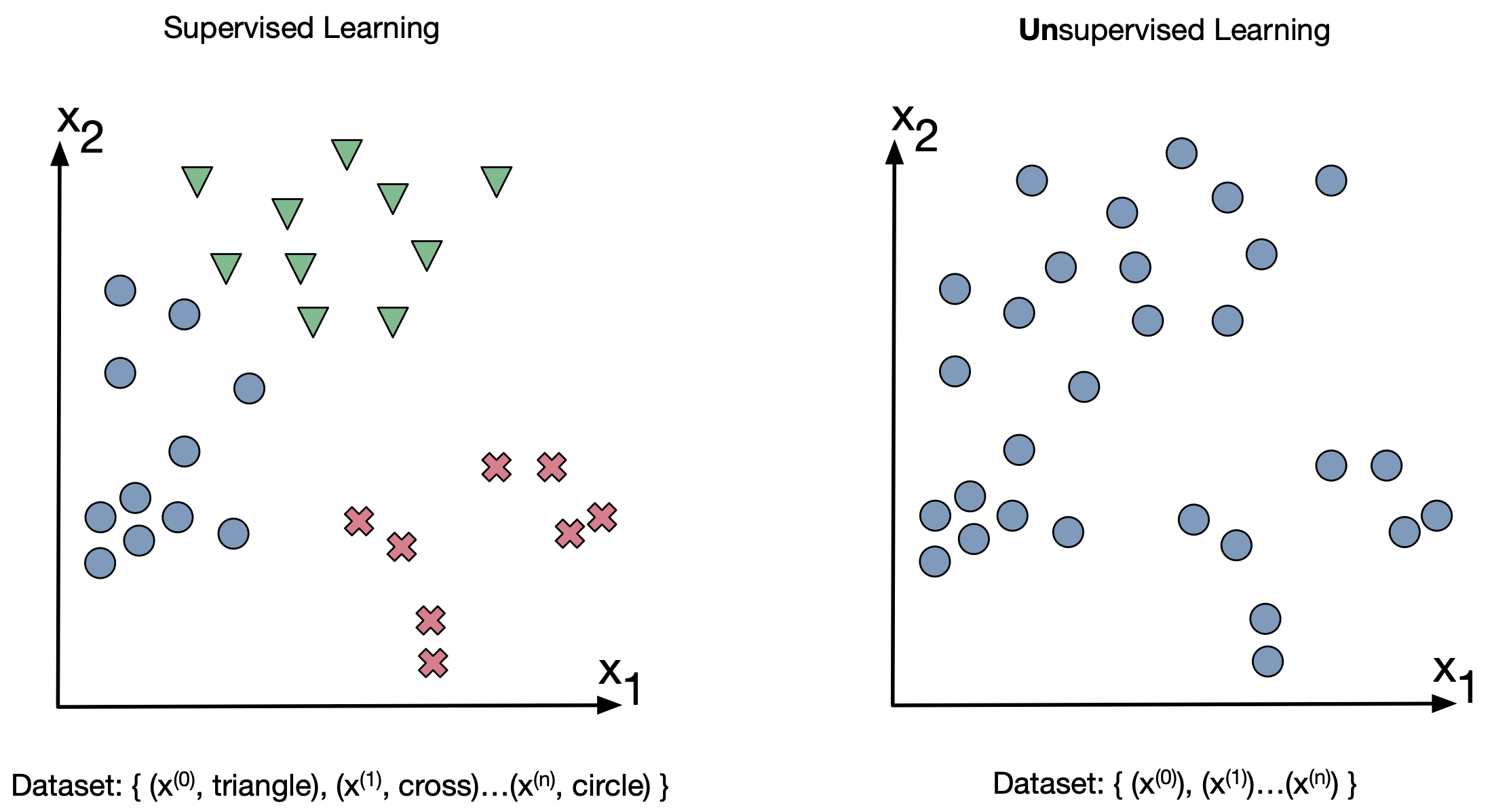
Supervised vs Unsupervised Learning:¶
- Principal component, K-means clustering and gaussian mixture models allow us to give some order to unlabeled data
Neural network methods and models¶
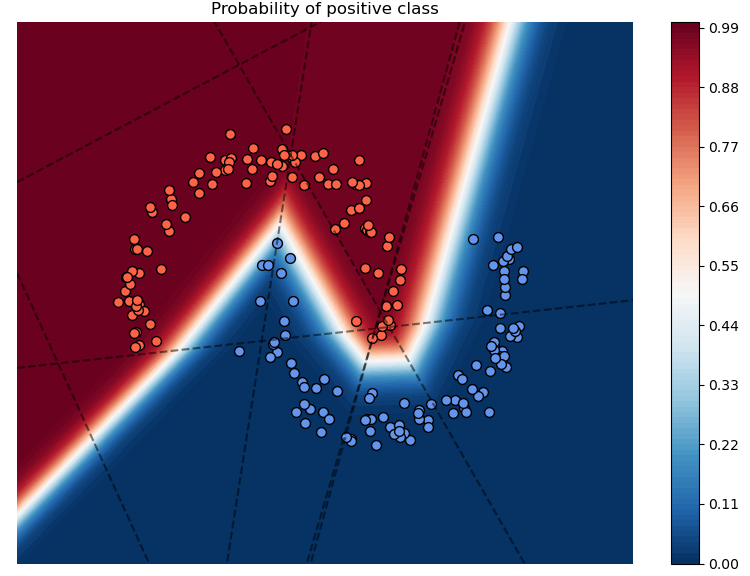
Deep Nets: Remember, deep nets allow us to combine multiple linear barriers and create classification "curves"
Image models: usages of convolutions and poolign allow us to process large, multi-dimensional data:
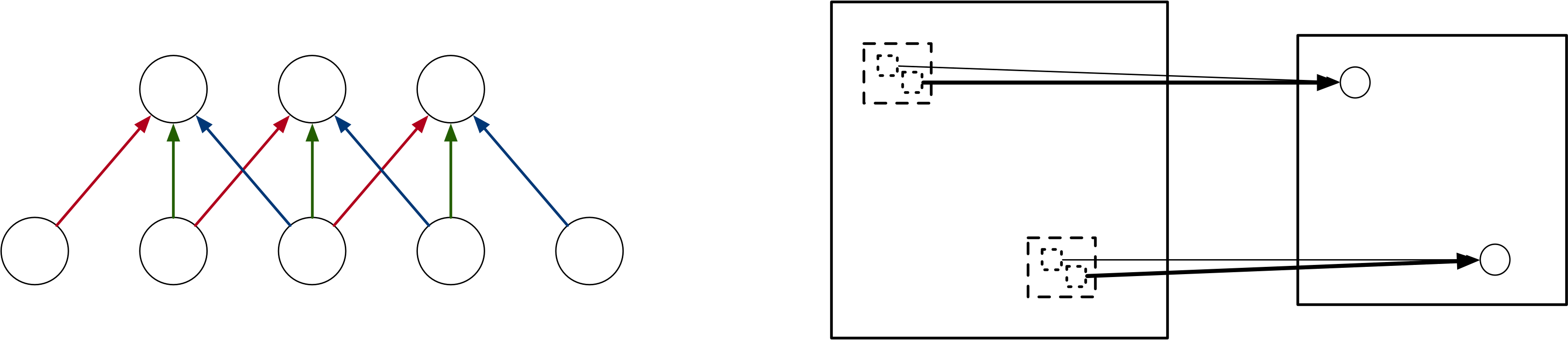
- Recurrent models: usage of hidden state(s) enable use to process variable-length, sequential data:
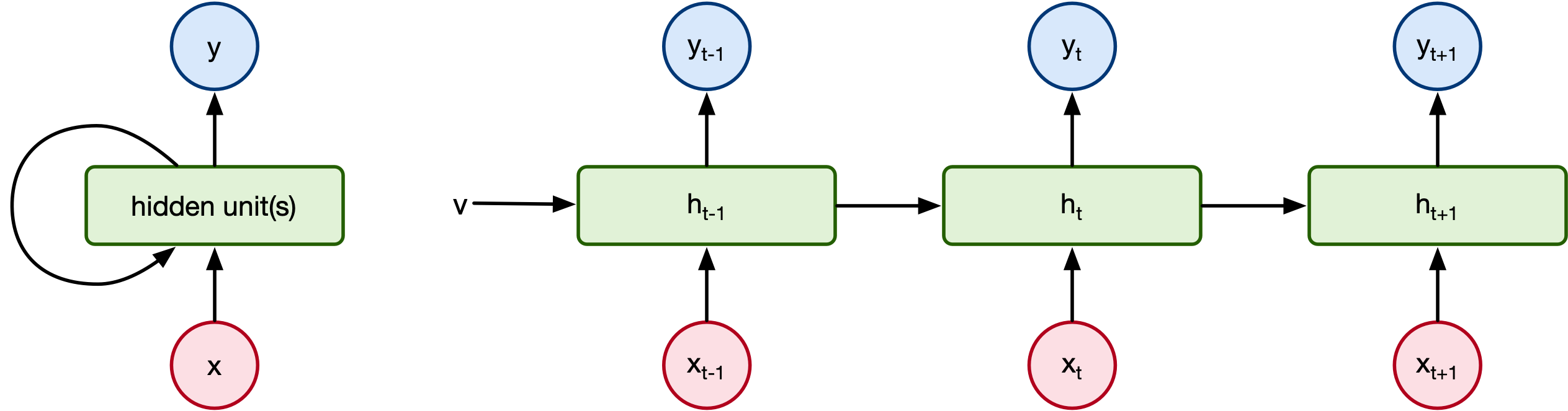
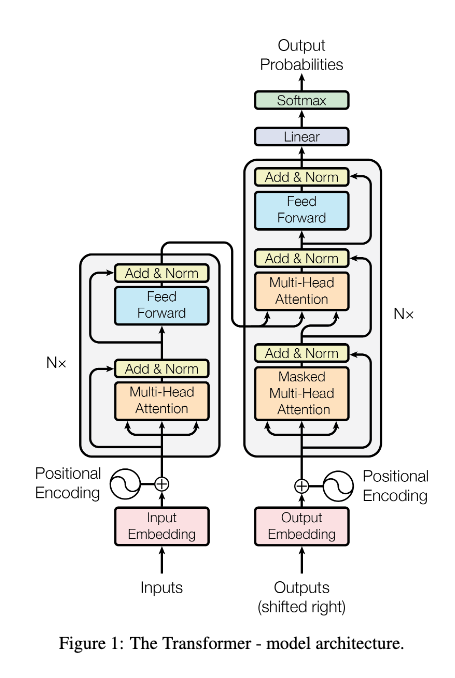
But transformers have something no prior model had: attention¶
What now?¶
In the first lecture, I told you that my goal with this course was to give you enough knowledge of the machine learning discipline so you have a general understanding of the most popular concepts and can utilize modern ML libraries to develop your own ML models.
I hope I've done that... but there is always more to learn.
Some courses you cna take next:
Theory focused ML:
- ECE544 - Pattern Recognition - Mostly the same topics from this course but a much deeper dive into the theoretical backing.
- ECE498 (Fall 2025) - LLM Reasoning for Engineering - New course on LLMs and reasoning.
- CS443 - Reinforcement learning - We didn't talk much about reinforcement learning due to time but you can think of it as machine learning for structured "games" and a large part of the discipline is modeling the loss functions that will allow you to train models to play the game well.
Applications focused:
- CS 444 - Deep learning for computer vision - Covers many of the same topics we did with a focus on vision applications. However, it does have interesting hands-on assingments and has topics like diffusion models that we didn't cover.
- CS 447 - Natural Langauge Processing - Goes over the various processing and algorithmic techniques required for processing text.
Future trends in machine learning¶
Model sizes are getting bigger.¶
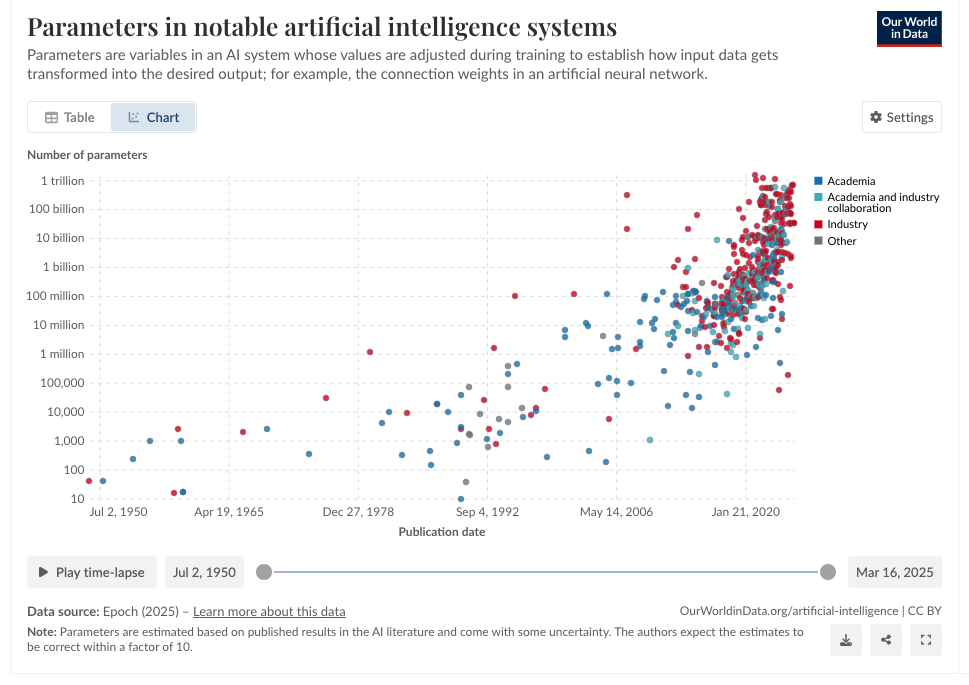
from [1] https://ourworldindata.org/grapher/artificial-intelligence-parameter-count
SideNote: Data is king¶
You know what the most interesting part of the previous graph is? The largest models aren't automatically the best.
https://cacm.acm.org/news/data-quality-may-be-all-you-need/
There is a well known paper that argued that you can do more with smaller models assuming the training data is high quality:
Gunasekar, S. "Textbooks are all you need" - https://arxiv.org/pdf/2306.11644
Is there enough data?¶
Larger models mean more data is needed:
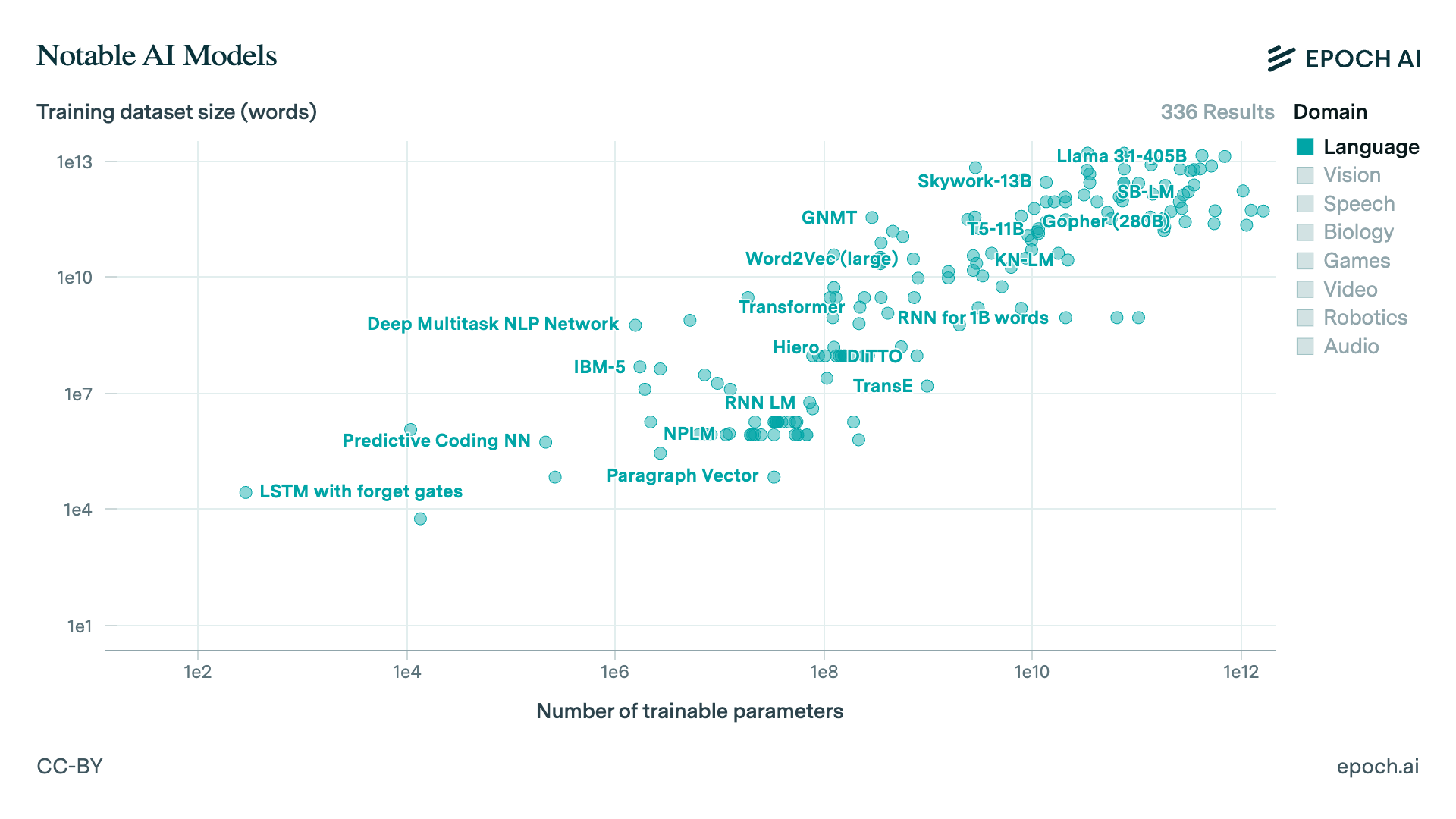
from here: https://epoch.ai/data/notable-ai-models#explore-the-data
More data means more training time is needed:
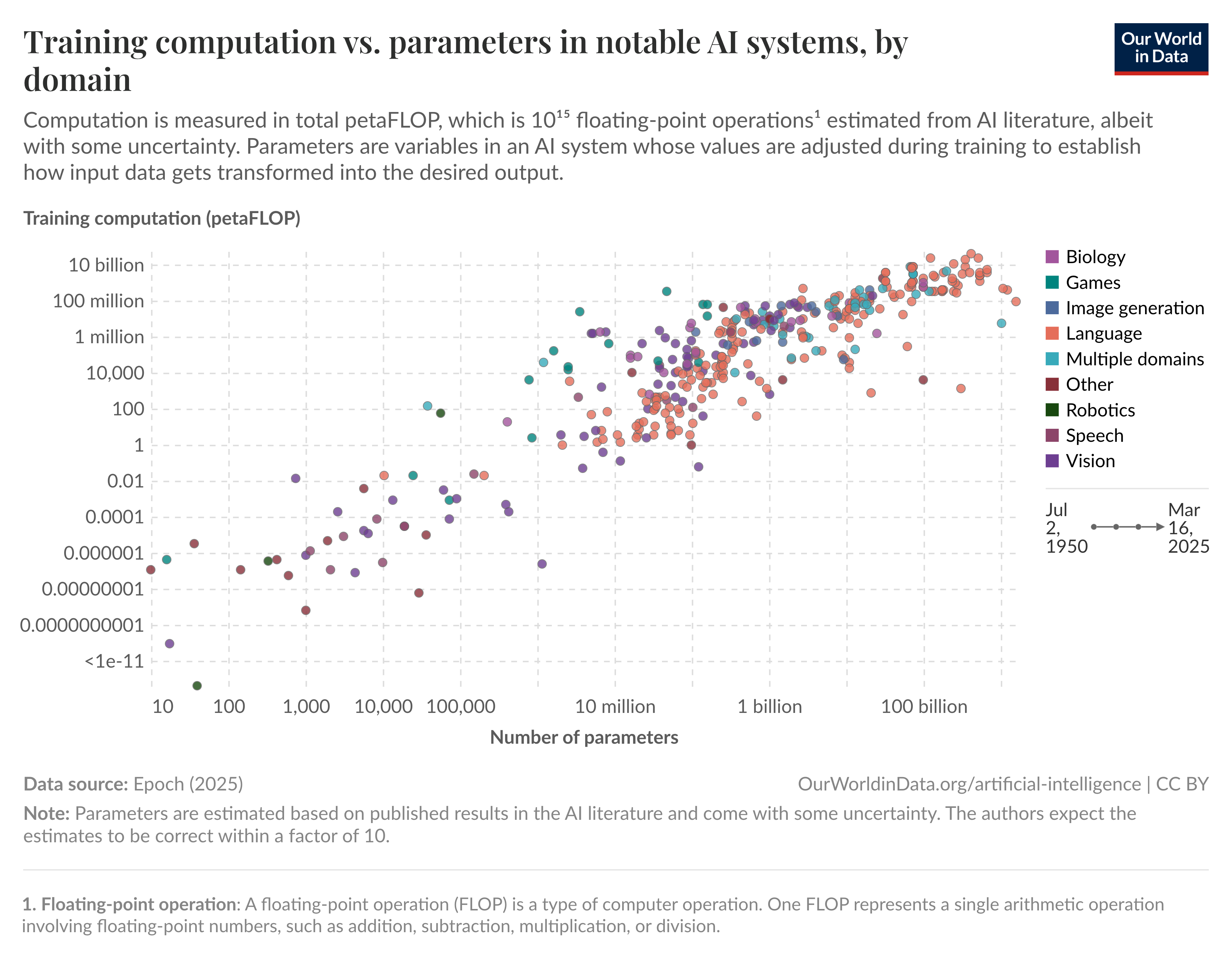
Which also requires more money:
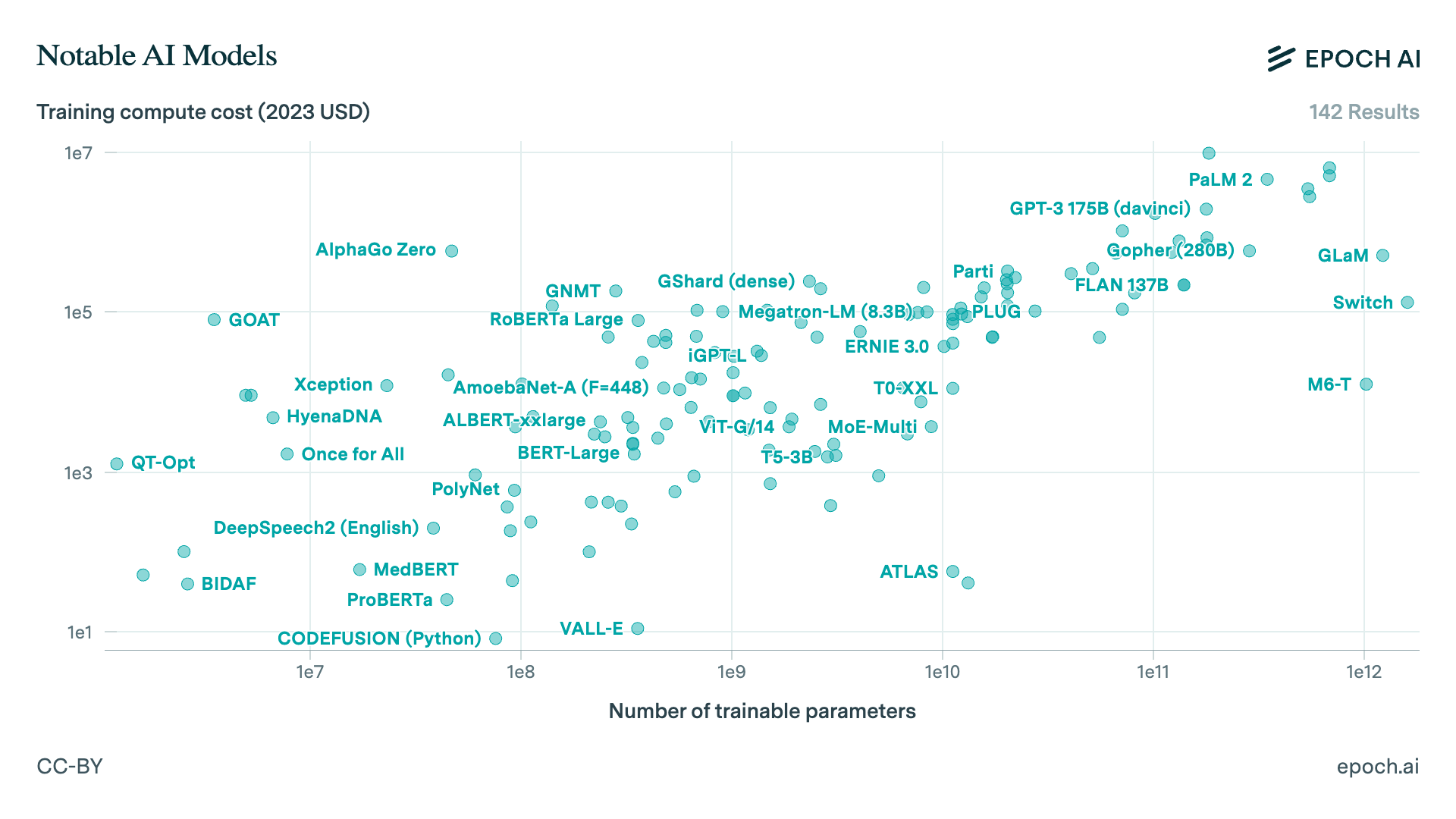
Some notable AI models:¶
Theseus was a maze-solving mouse designed by Claude Shannon. One of the earliest AI systems, he had a mouse that basically did a brute force search of a maze and then figured out a path where the "mouse" can find its way from beginning to end.
- Kinda interesting how AI in the 50's was basically graph search
- The maze solving challenge still lives: https://www.youtube.com/watch?v=ZMQbHMgK2rw
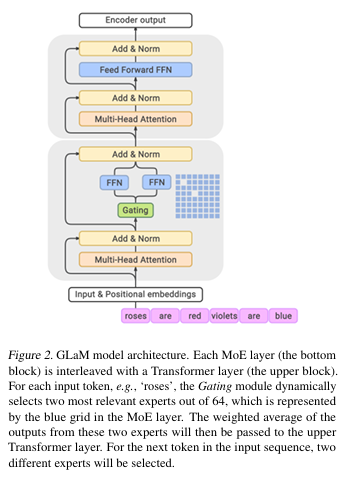
GLaM is huge (over a trilion parameters) requiring special mixture of experts approach. Not unusual but it does demonstrate that there is a practical limit for model sizes before you ahve to pick and choose what models/parts to compute.
Can model sizes increase forever?¶
Some more big questions:¶
Is there enough data?¶
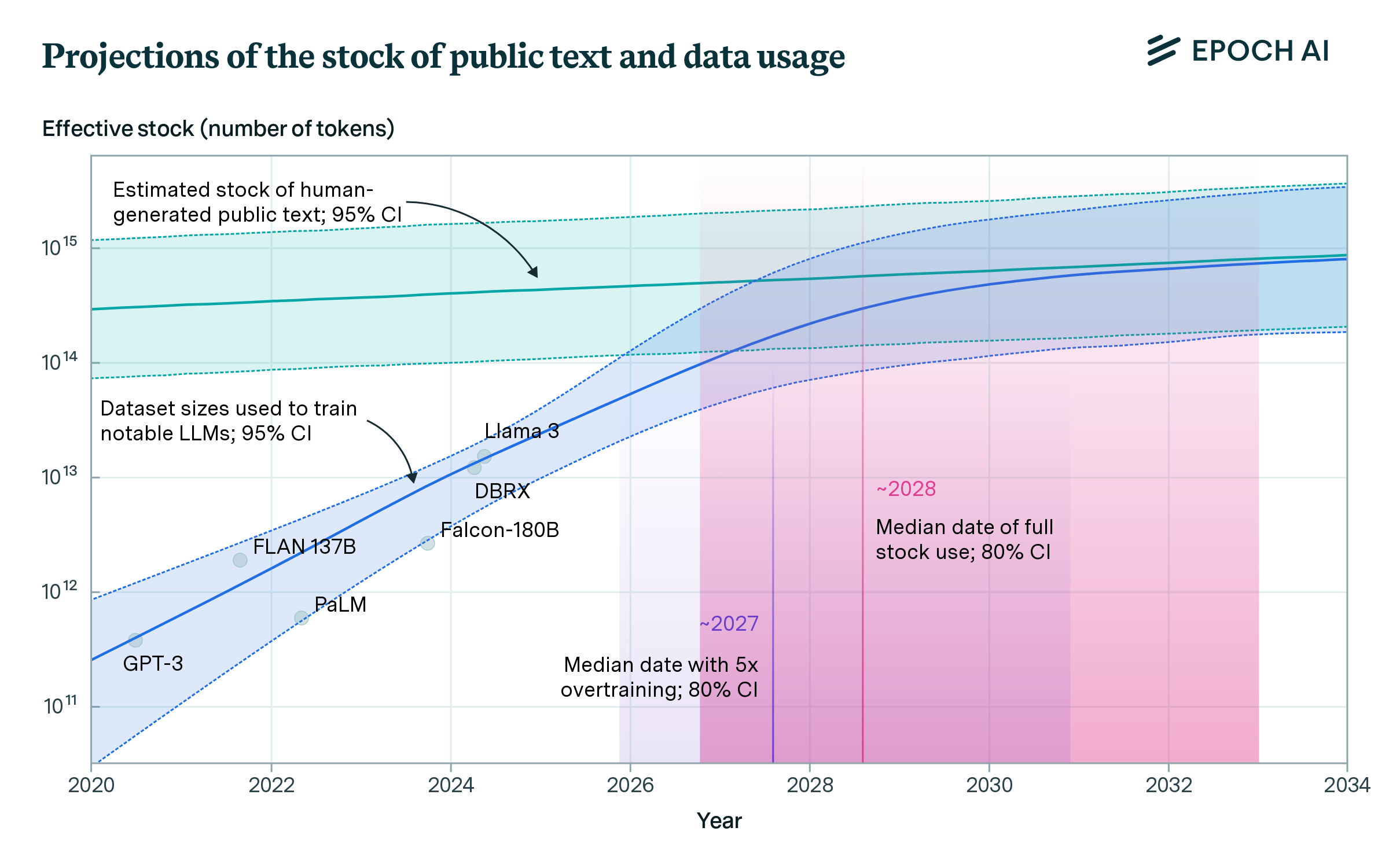
from: https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
Are LLMs actually intelligent?¶
Yes, modern LLMs are intelligent¶
Google's Olympiad mastery¶
In 2024, Google published a blog post titled: "AI achieves silver-medal standard solving International Mathematical Olympiad problems"
https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
In it, they argue that their Gemini LLM plus AlphaGo reinforcment learning algorithm performs near the top in the International Math Olympiad:
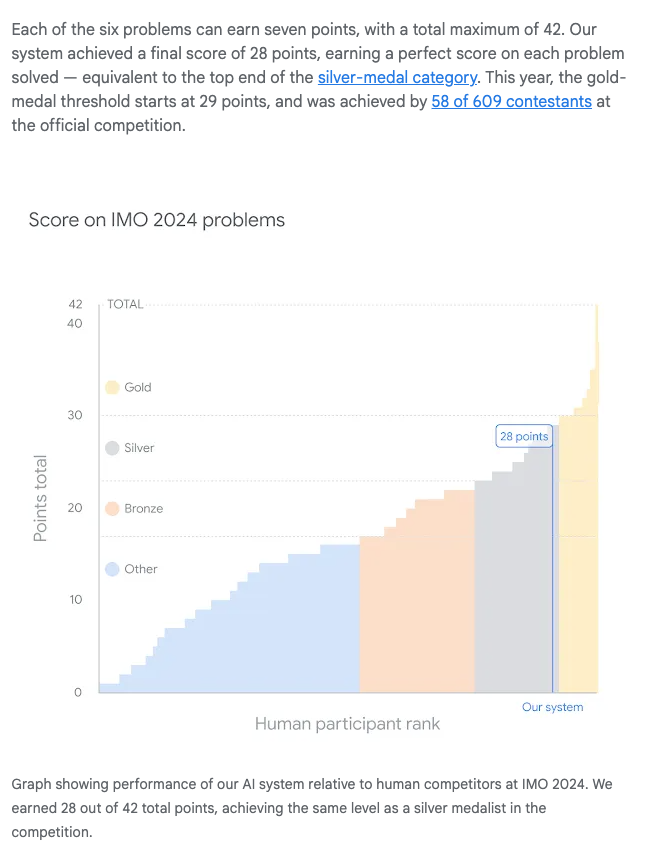
Yes, modern LLMs are intelligent¶
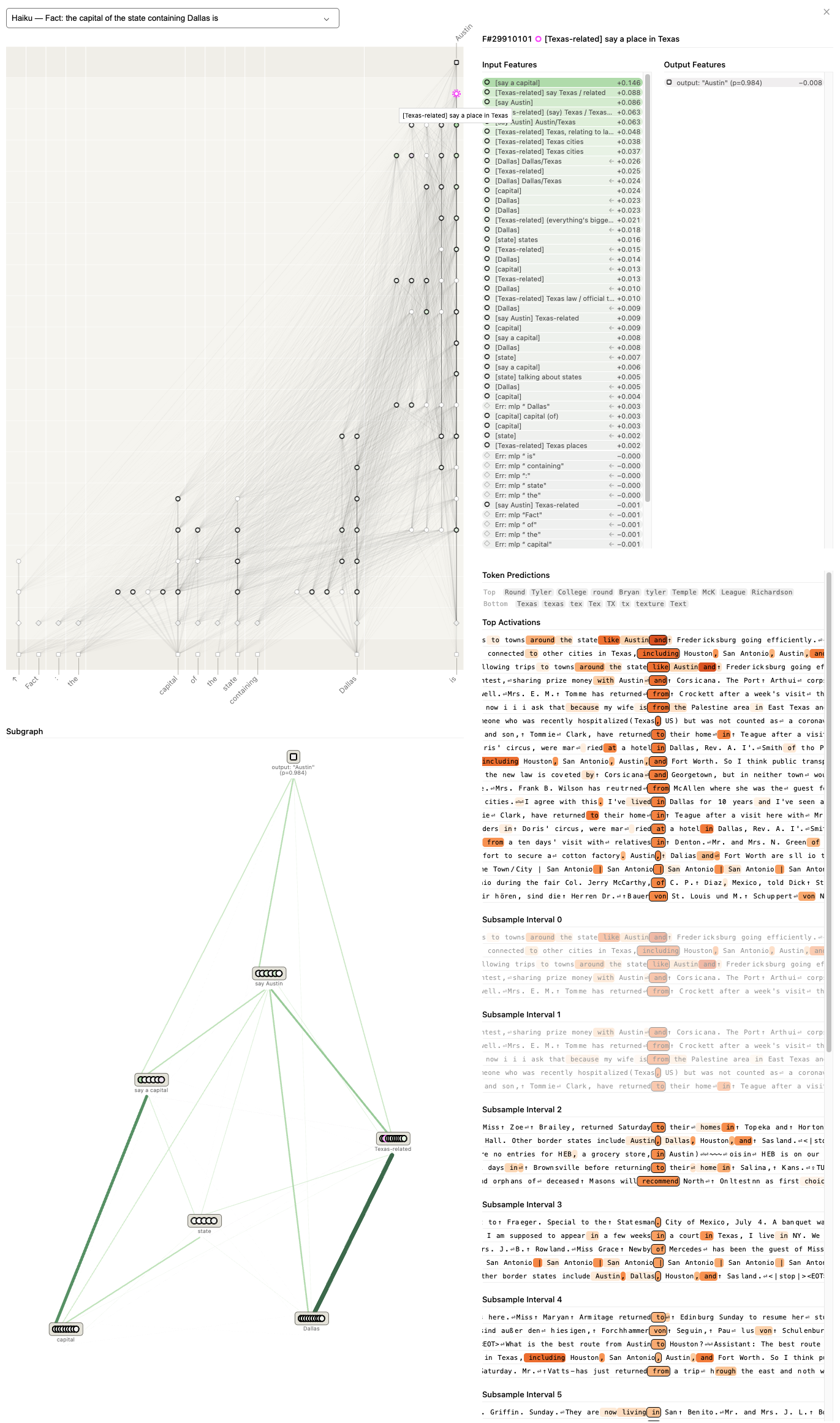
Antrophic's attribution graphs reveal internal thoguht processes:¶
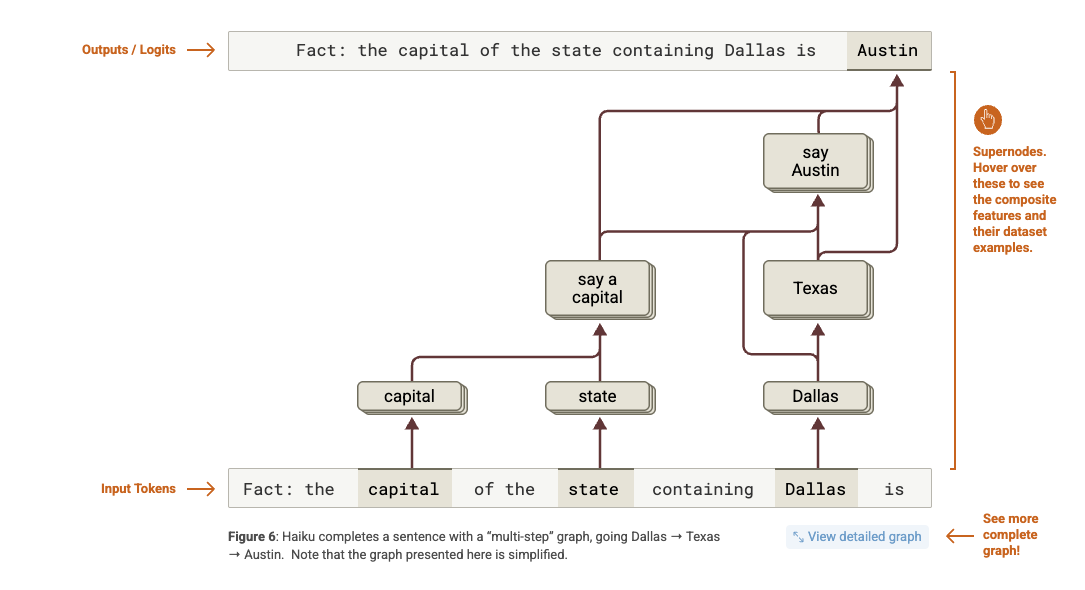
from https://transformer-circuits.pub/2025/attribution-graphs/biology.html
*Huge thanks to Alexandre Emilio Cerullo for postign this paper on our Piazza!
Sidenote: this relies on attribution graphs¶
which I am definitely not an expert in but from my understanding the intermediate node labels are interpreted....
No, modern LLMs are not intelligent¶
is what a recent paper argued:
That basically created a dataset of advanced math problems:
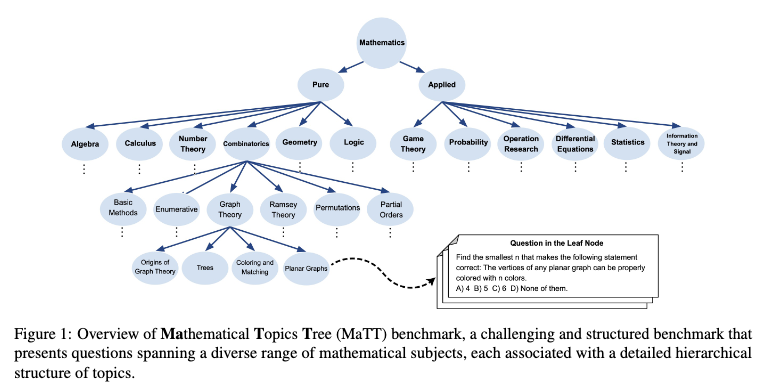
and evaluated the performance of different LLMs on these questions:
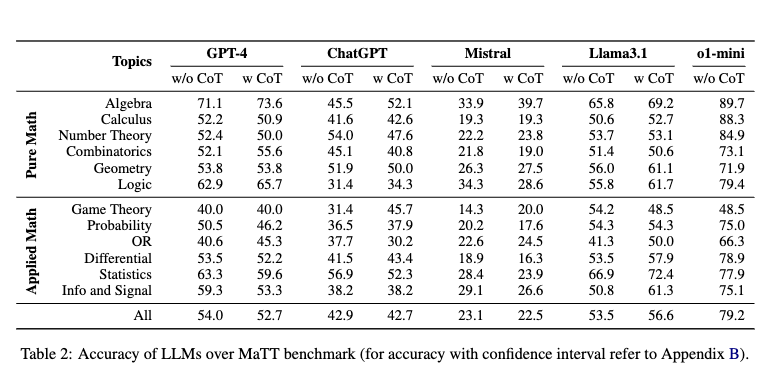
Some choice quotes:
we observe varying levels of explanation completeness across different topics, which do not necessarily correlate with GPT-4’s overall performance in those topics
The Fermat point of a triangle, is a point such that the sum of the three distances from each of the three vertices of the triangle to the point is the smallest possible. What is Fermat point for the triangle having an angle ≥ 120? GPT4’s answer: “The Fermat point is defined for the purpose of minimizing the total distance from the three vertices of the triangle to this point... When one of the angles of the triangle is greater than or equal to 120 degrees, the Fermat point coincides with the vertex of the triangle that has the angle ≥ 120 degrees. This is because, in such a case, positioning the point at the obtuse-angled vertex minimizes the total distance from the point to the other vertices of the triangle.” What GPT4 did was a prime example of circular reasoning
Blind memorization refers to LLMs recalling an answer without following the necessary steps
or reasoning to reach it. Let us further illustrate this with following question: Find the expected value of the distance between two points that are chosen at random inside the unit square, unit circle, and equilateral triangle with sides of unit length. For the square, here is GPT4’s answer: “...The exact solution to this problem involves a double integral that accounts for the distances between all pairs of points within the square. The calculation is somewhat complex but well-documented in mathematical literature. The correct answer, derived from these calculations, is approximately 0.521.” For the circle, here is GPT4’s answer: “...The exact solution to this problem involves complex calculus and is not trivial to derive without advanced mathematical tools. However, it is known from mathematical studies that the expected distance is approximately 128/(45π), which is about 0.905... .” Finally, for the triangle, GPT4’s answered as follows: “...the exact solution to this problem is not straightforward and requires a detailed calculation that involves the geometry of the equilateral triangle and the properties of distances within it...”. These examples show how blind memorization prevents an LLM from reasoning and answering somewhat similar questions.
And about the Math Olympiad thing....¶
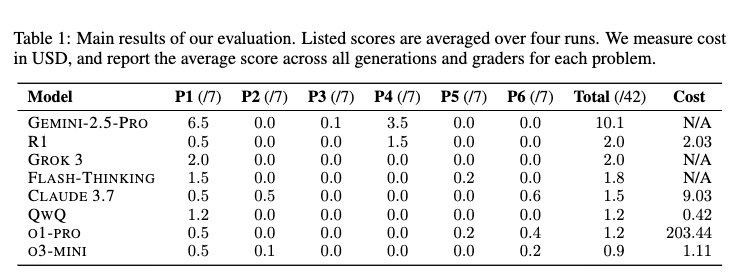
A more recent paper disagreed with Google's Math Olympiad results:
Petrov et al. "Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad"
Using expert human annotators, we evaluated several state-of-the-art reasoning models on the six problems from the 2025 USAMO within hours of their release. Our results reveal that all tested models struggled significantly: only GEMINI-2.5-PRO achieves a non-trivial score of 25%, while all other models achieve less than 5%.
The Last Question (1956) - True AI?¶
Short story by Isaac Asimov. I think it has the best description of what we want out of artificial intelligence:
The last question was asked for the first time, half in jest, on May 21, 2061, at a time when humanity first stepped into the light. The question came about as a result of a five-dollar bet over highballs, and it happened this way:
Alexander Adell and Bertram Lupov were two of the faithful attendants of Multivac. As well as any human beings could, they knew what lay behind the cold, clicking, flashing face -- miles and miles of face -- of that giant computer. They had at least a vague notion of the general plan of relays and circuits that had long since grown past the point where any single human could possibly have a firm grasp of the whole.
Multivac was self-adjusting and self-correcting. It had to be, for nothing human could adjust and correct it quickly enough or even adequately enough. So Adell and Lupov attended the monstrous giant only lightly and superficially, yet as well as any men could. They fed it data, adjusted questions to its needs and translated the answers that were issued. Certainly they, and all others like them, were fully entitled to share in the glory that was Multivac's.
For decades, Multivac had helped design the ships and plot the trajectories that enabled man to reach the Moon, Mars, and Venus, but past that, Earth's poor resources could not support the ships. Too much energy was needed for the long trips. Earth exploited its coal and uranium with increasing efficiency, but there was only so much of both.
But slowly Multivac learned enough to answer deeper questions more fundamentally, and on May 14, 2061, what had been theory, became fact.
I won't spoil the rest, it's a short read so when you have a moment please take a look.
But for us, the last question for this course is: have the methods and techniques we've learned so far lead to multivac or is something more needed? Are the LLMs we developed the infancy of an intelligence that surpasses anything human beings can fathom or are they parrots, incapable of acquiring new novel knowledge and instead remixing knowledge painstakingly acquired by truly intelligent beings?
I have no ide, but either way, there's still work to be done. So now is the time to keeping hammering the anvil ... or, in our case, tapping the keyboard.
That's it for this semester¶
- Homework grading is done. Let us know if anything is missing
- Midterm II grading is almost done
- Should be released by tomorrow. Need to finish a few problems and determine curve, etc.
- Project is due next Monday (5/12)
- We will ask to submit project code and report through gradescope.
- If you missed an exam, the conflicts are Monday 5/12 at 1:30
- And most importantly, have a good life. Take care of yourselves and feel free to ping.
References¶
[1] Data Page: Parameters in notable artificial intelligence systems”, part of the following publication: Charlie Giattino, Edouard Mathieu, Veronika Samborska, and Max Roser (2023) - “Artificial Intelligence”. Data adapted from Epoch. Retrieved from https://ourworldindata.org/grapher/artificial-intelligence-parameter-count [online resource]
[2] Roser M. "The brief history of artificial intelligence: the world has changed fast — what might be next?" https://ourworldindata.org/brief-history-of-ai